网页乱码,就是指平时我们打开一个网页它的内容看起来奇奇怪怪,不是正常的中文形态,那会不会是一种特殊的非中文系语言呢?有可能,但是可以分辨!

正常的非中文系语言

中文乱码
那么为什么会发生乱码呢?首先,需要明确以下几点:
1,乱码不是由于你的设备原因导致
2,不只有中文会产生乱码,其它语言也会有乱码
3,乱码的根本原因是因为互联网的原因
互联网方便的把全地球的人们连接在一起,于是网络上的内容可以是任意一种语言产生的,然后当它传播到另外一种语言使用者(比如中文)面前的时候,因为他们所处的互联网环境不同,而计算机又不足够智能的分辨应该以什么样的语言形式展示内容的时候就发生了页面乱码。
那么网页乱码怎么解决呢?同样的,还是需要明确下面几点:
1,遇到网页乱码不要慌,你的设备没有问题
2,网页乱码问题绝对不需要内容阅读者即用户自己解决
3,如果你好奇想自己解决,那么只需要通过搜索引擎搜索关键字:“ie/360/chrome 网页编码设置”,根据出来的内容随便找一篇照着点几次鼠标就可以了!
这篇常识的目的是告诉你,互联网后来是如何解决网页乱码的,也就是前面提到的,网页乱码不需要用户自己解决。
随着互联网越来普及,乱码的问题起初非常的容易发生,当然了,发生的原因也很简单,内容所处的语言环境不同,计算机不知道该怎么显示了。
于是各个国家的网络权威机构就一起组织了一个联盟,专门用来解决网络上内容乱码的问题,并且给这个联盟起了一个名字叫:Unicode

组织建好之后该是商量具体的解决方案了!因为在这之前,每个国家都有自己的语言在计算机中的表示形式(实际就是一张表格),而且随着各国语言的变迁,这张表格还会时不时升级一下。
那怎么办呢?最后,Unicode 组织确定了一种非常便捷的解决方法。就是让各个国家把自己语言在计算机中的表示形式表格,都提交给 Unicode 组织,由 Unicode 组织统一管理,然后把它们都合并到一起形成一张非常大的表格,再交给计算机厂商,在它们出厂计算机的时候默认的把这张巨大的表格都存放到计算机中,这样每台计算机就相当于拥有全世界各种语言的表示形式。
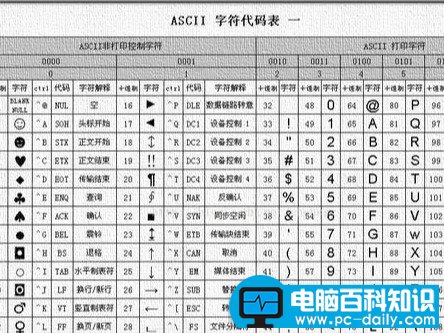
这样当一种语言的内容传播到另外一种语言使用者面前的时候,计算机就能够以某种机制监测到使用者的语种,然后使用对应的表示形式来显示内容,这样就不会发生乱码了。
但是正如我们想象的,这张表格非常的庞大,放到用户的计算机里的时候也是要占用一定的空间呢,所以 Unicode 组织就想办法怎么样尽可能的既能让这张表格表示尽可能多的语言,又能尽可能的小。
于是就出现了“编码”这个概念!编码的本质就是说针对不同的语言,使用的存储空间不一样!比如,汉字和英文字母的占用空间就完全不同,这样就了各种形式的编码方案,网络上被人们熟知的编码方案包括:ASCII,UTF8,GBK,GB2312等,目前国际上最通用的编码方案是UTF8。
现在想必大家都知道乱码的原因了,那么你知道为什么现在我们很少遇到网页乱码了吗?
哈,没错,因为我们的电脑都升级换代了呀 ^_^