我们在做WEB自动化时,最根本的就是操作页面上的元素,首先我们要能找到这些元素,然后才能操作这些元素。工具或代码无法像我们测试人员一样用肉眼来分辨页面上的元素。那么我们怎么来定位他们呢?
1.id定位
从上面定位到的搜索框属性中,有个id="kw"的属性,我们可以通过这个id定位到这个搜索框
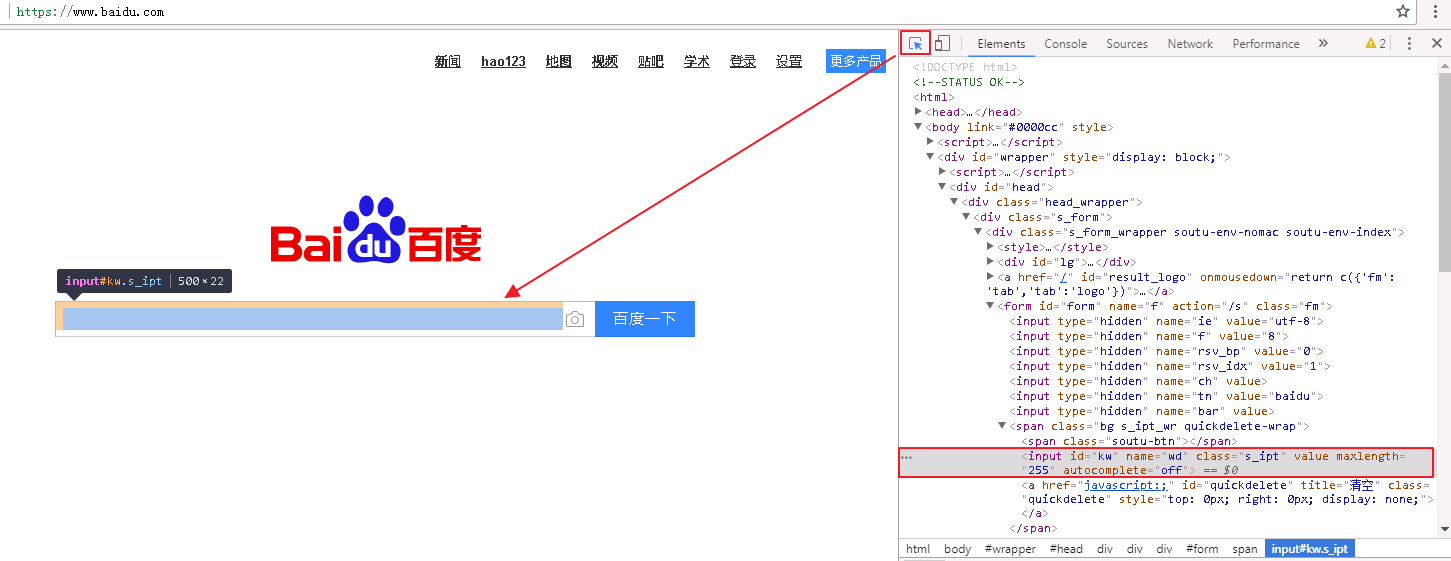

2.name定位
根据元素的name来定位属性,但name并不是唯一的。

3.class name定位
如果class属性含有空格,那么取其中一个不重复的字段就可以了
driver.find_element_by_class_name("s_ipt")
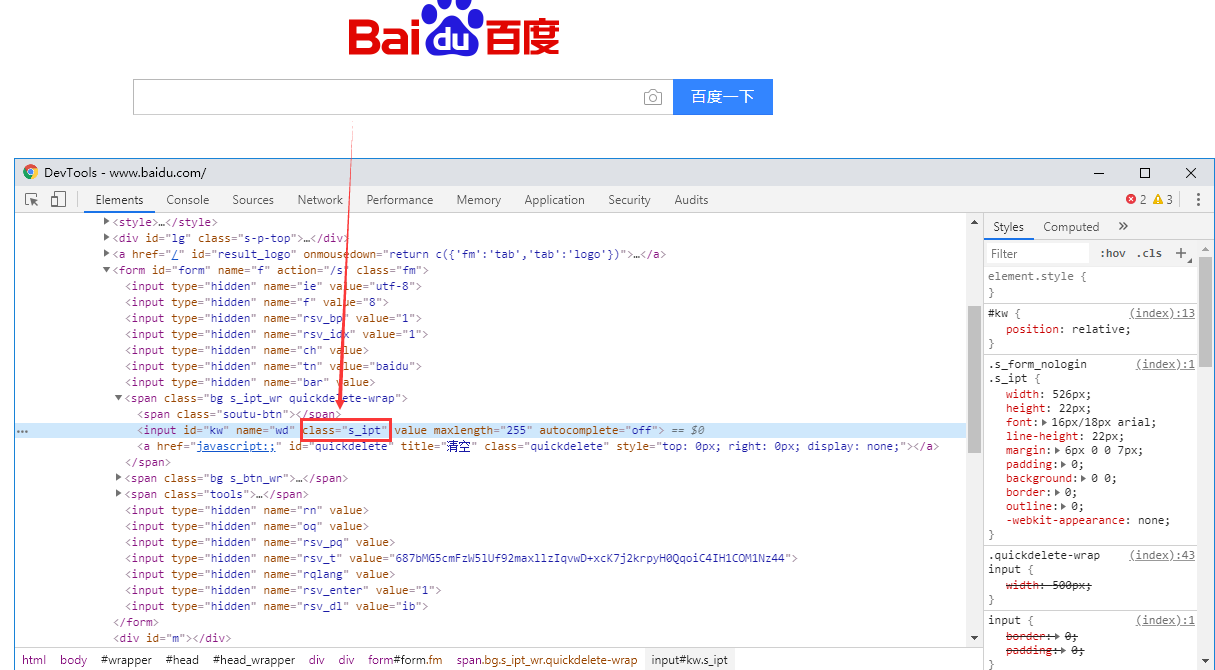
4.tag定位
如果懂HTML知识,我们就知道HTML是通过tag来定义功能的,比如input是输入,table是表格,等等...。每个元素其实就是一个tag,一个tag往往用来定义一类功能,我们查看百度首页的html代码,可以看到有很多div,input,a等tag,所以很难通过tag去区分不同的元素。基本上在我们工作中用不到这种定义方法,仅了解就行。下面代码仅做参考,运行时必定报错

5.link_text和partial_link_text定位
link_text和partial_link_text是作用于链接a标签的,link_text用于全部匹配文本值,partial_link_text用于部分匹配文本值
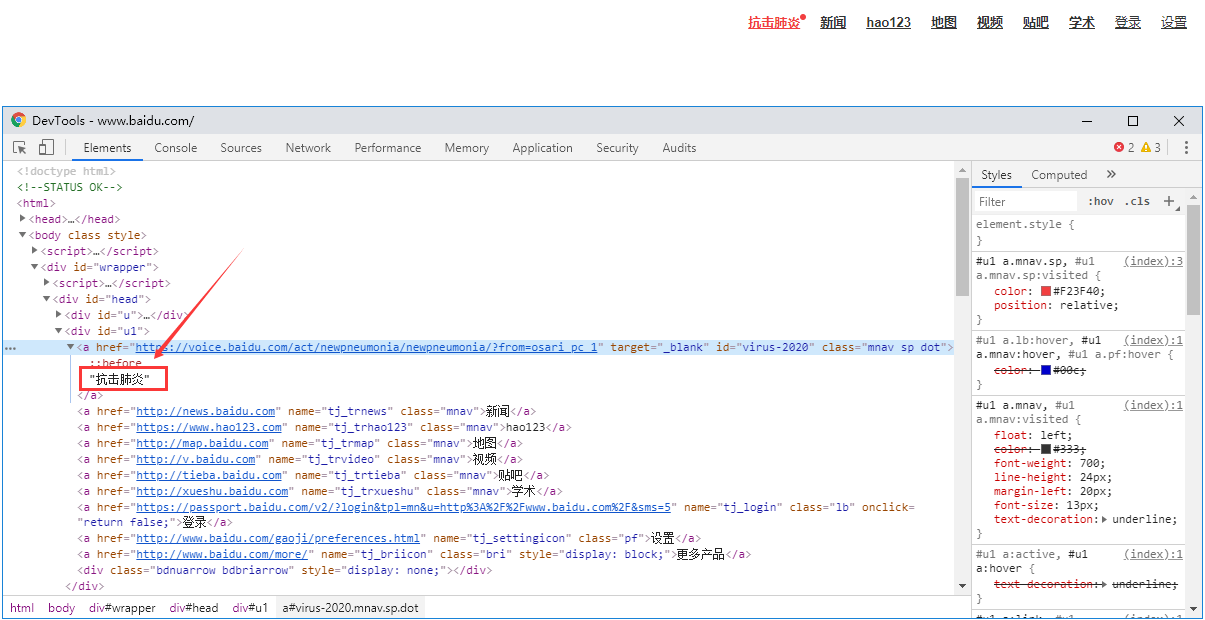

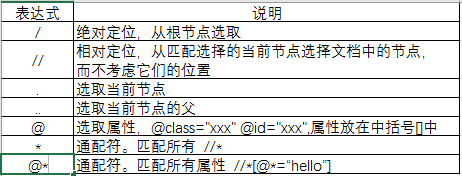
6.xpath定位
xpath是XML路径语言,它可以用来确定xml文档中的元素位置,通过元素的路径来完成对元素的查找。HTML就是XML的一种实现方式,所以xpath是一种非常强大的定位方式。

7.css定位
如果有css基础的话就应该可以看懂,一般class是用.标记,id是用#标记,标签名直接写具体标签名就好了。