一 前言
本文将针对开发过程中依旧经常出现的SQL编码缺陷,讲解其背后原理及形成原因。并以几个常见漏洞存在形式,提醒技术同学注意相关问题。最后会根据原理,提供解决或缓解方案。
二 SQL注入漏洞的原理、形成原因
SQL注入漏洞,根本上讲,是由于错把外部输入当作SQL代码去执行。目前最佳的解决方案就是预编译的方式。
SQL语句在执行过程中,需要经过以下三大基本步骤:
- 代码语义分析
- 制定执行计划
- 获得返回结果
而一个SQL语句是由代码和数据两部分,如:
SELECT id, name, phone FROM userTable WHERE name = 'xiaoming';
SELECT id, name, phone FROM userTable WHERE name = 是代码,'xiaoming'是数据。
而预编译,以Mybatis为例,就是预先分析带有占位符的语义:
如SELECT id, name, phone FROM userTable WHERE id = #{name};
然后再将数据'xiaoming',传入到占位符。这样一来,错开来代码语义分析阶段,也就不会被误认为是代码的一部分了。
在最早期,开发者显式使用JDBC来自己创建Connection,执行SQL语句。这种情况下,如果将外部可控数据拼接到SQL语句,且没有做充分过滤的话,就会产生漏洞。这种情况在正常的业务开发过程中已经很少了,按照公司规定,无特殊情况下,必须使用ORM框架来执行SQL。
但目前部分项目中,仍会使用JDBC来编写一些工具脚本,如DataMerge.java 、DatabaseClean.java,借用JDBC的灵活性,通过这些脚本来执行数据库批量操作。
此类代码不应该出现在线上版本中,以免因各种情况,被外部调用。
三 直接使用Mybatis
1 易错点
目前大部分的平台代码是基于Mybatis来处理持久层和数据库之间的交互的,Mybatis传入数据有两种占位符{}和#{}。{}和#{}。{}可以理解为语义分析前的字符串拼接,讲传入的参数,原封不动地传入。
比如说
SELECT id, name, phone FROM userTable WHERE name = '${name}';
传入name=xiaoming后,相当于
SELECT id, name, phone FROM userTable WHERE name = 'xiaoming';
实际应用中
SELECT id, name, phone FROM userTable WHERE ${col} = 'xiaoming';
传入col = "name",相当于
SELECT id, name, phone FROM userTable WHERE name = 'xiaoming';
就像预编译原理介绍里讲的一样,使用#{} 占位符就不存在注入问题了。但有些业务场景是不可以直接使用#{}的。
比如order by语法中
如果编写SELECT id, name, phone FROM userTable ORDER BY #{}; ,执行时是会报错的。因为order by后的内容,是一个列名,属于代码语义的一部分。如果在语义分析部分没有确定下来,就相当于执行SELECT id, name, phone FROM userTable ORDER BY 。肯定会有语法错误。
再比如like场景下
SELECT id, name, phone FROM userTable WHERE name like '%#{name}%';
#{}不会被解析,从而导致报错。
in 语法和 between语法都是如此,那么如何解决这类问题呢?
2 正确写法
order by(group by)语句中使用${}
1.使用条件判断
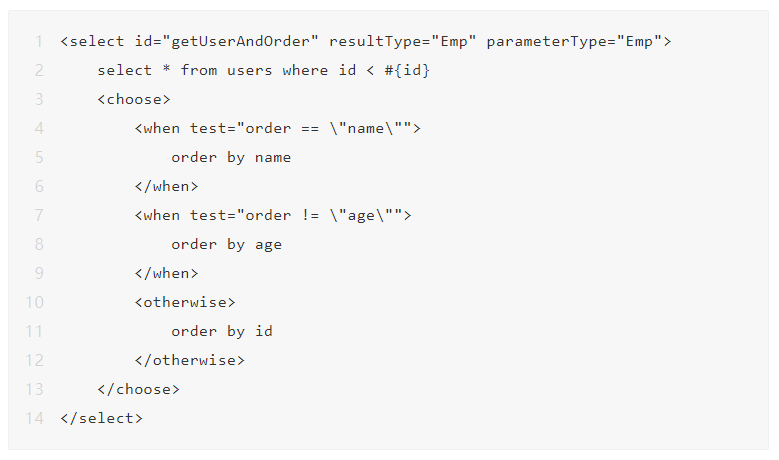
2.使用全局过滤机制,限制order by后的变量内容只能是数字、字母、下划线。
如使用正则过滤:
keyword = keyword.replaceAll("[^a-zA-Z0-9_\s+]", "");
这里需要注意,过滤需要使用白名单,不能使用黑名单,黑名单无法解决注入问题。
LIKE语句
由于需要like中的关键词需要包裹在两个%符号中,因此可以使用CONCAT函数进行拼接。

注意不要用 CONCAT('%','${stuName}','%') ,这样仍然存在漏洞。也就是说,使用$符号是不对的,使用#符号才安全。
IN语句
类似于like语句,直接使用#{}会报错,常见的错误写法为:
tenant_id in (${tenantIds})
正确的写法为:

四 Mybatis-generator使用安全
繁重的CRUD代码压力下,开发者慢慢开始通过Mybatis-generator、idea-mybatis-generator插件、通用Mapper、Mybatis-generator-plus来自动生成Mapper、POJO、Dao等文件。
这些工具可以自动的生成CRUD所需要的文件,但如果使用不当,就会自动产生SQL注入漏洞。我们以最常用的org.mybatis.generator为例,来讲解可能会出现的问题。
1 动态语句支持
Mybatis-generator提供来一些函数,帮助用户把SQL的各个条件连接起来,比如多个参数的like语法,多个参数的比较语法。为了保证使用的简洁性,需要使用将一些语义代码拼接到SQL语句中。而如果开发者使用不当,将外部输入也传入了{}占位符。就会产生漏洞。
2 targetRuntime参数配置
在配置generator时,配置文件generator-rds.xml中有一个targetRuntime属性,默认为MyBatis3。在这种情况下,会启动Mybatis的动态语句支持,启动enableSelectByExample、enableDeleteByExample、enableCountByExample 以及 enableUpdateByExample功能。
以enableSelectByExample为例,会在xml映射文件中代入以下动态模块:

开发者include该模块就可以添加where条件,但如果使用不当,就会导致SQL注入漏洞:

并使用自定义的参数添加函数:
public Criteria addKeywordTo(String keyword) {
StringBuilder sb = new StringBuilder();
sb.append("(display_name like '%" + keyword + "%' or ");
sb.append("org like '" + keyword + "%' or ");
sb.append("status like '%" + keyword + "%' or ");
sb.append("id like '" + keyword + "%') ");
addCriterion(sb.toString());
return (Criteria) this;
}
目的是为了实现同时对display_name、org、status、id的like操作。其中addCriterion是Mybatis-generator自带的函数:
protected void addCriterion(String condition) {
if (condition == null) {
throw new RuntimeException("Value for condition cannot be null");
}
criteria.add(new Criterion(condition));
}
这里的误区在于,addCriterion本身提供了多个条件的支持,但开发者认为需要自己把多个条件拼接起来,一同传入addCriterion方法。如同案例中的代码一样,最终传入addCriterion的只有一个参数。从而执行Example_Where_Clause语句中的:

也就是说,开发者把自己拼接的SQL语句,直接代入了${criterion.condition}中,从而导致了漏洞的产生。
而按照Mybatis-generator的文档,正确的写法应该是:
public void addKeywordTo(String keyword, UserExample userExample) {
userExample.or().andDisplayNameLike("%" + keyword + "%");
userExample.or().andOrgLike(keyword + "%");
userExample.or().andStatusLike("%" + keyword + "%");
userExample.or().andIdLike("%" + keyword + "%");
}
or方法负责创建Criteria,这时触发的逻辑就是

${criterion.condition}被替换为了没有单引号的like,like作为语义代码,在语义分析前拼接到了SQL语句中,而"%" + keyword + "%"会作为数据添加到预编译#{criterion.value}中去,从而避免了注入。
类似的,也提供了In语法的安全使用方法:

Beetween的安全使用方法:
example.or()
.andField6Between(3, 7);
Mybatis-generator默认生成的order by语句也是使用${}直接进行拼接的:

如果没有对传入的参数进行额外的过滤的话,就会导致注入问题。
3 order by
除了自己写的SQL语句以外,Mybatis-generator默认生成的order by语句也是使用${}直接进行拼接的:

如果没有对传入的参数进行额外的过滤的话,就会导致注入问题。
PS: 实际扫雷过程中发现很多语句自动生成了order by语法,但上层调用时,并没有传入该可选参数。这种情况应当删除多余的order by语法。
4 其它插件
插件与插件之间的安全缺陷还不太一样,下面简单列举了常用的几种插件。
idea-mybatis-generator
这是IDEA的插件,可以在开发过程中,从IDE的层面,自动生成CRUD中需要的文件。使用该插件时,也有一些默认安全隐患需要注意。
1)自定义order by处理
like\in\between可以参照官方文档使用,无安全隐患。
但该插件没有内置的order by处理,需要自行编写,编写时,参考Case2
2)默认的IF条件前需要判断是否为空
插件默认生成的语法大致如下:

当ID参数为null时,if标签下的逻辑不会添加到SQL语句中,可能会导致DOS、权限绕过等漏洞。因此,参数传入查询语句前,需要确认不为空。
com.baomidou.mybatis-plus
- apply方法传参时,应当使用{}
- 自带的last方法,其原理是直接拼接到SQL语句的末尾,存在注入漏洞。
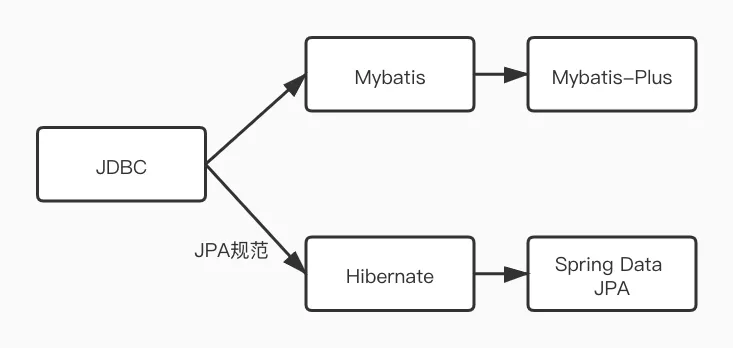
五 其它ORM框架
1 Hibernate
ORM全称为对象关系映射(Object Relational Mapping),简单地说,就是将数据库中的表映射为Java对象, 这种只有属性,没有业务逻辑的对象也叫做POJO(Plain Ordinary Java Object)对象。
Hibernate是第一个被广泛使用的ORM框架,它通过XML管理数据库连接,提供全表映射模型,封装程度很高。在配置映射文件和数据库链接文件后,Hibernate就可以通过Session对象进行数据库操作,开发者无需接触SQL语句,只需要写HQL语句即可。
Hibernate经常与Struts、Spring搭配使用,也就是Java世界的经典SSH框架。
HQL相较于SQL,多了很多语法限制:
- 不能查询未做映射的表,只有当模型之间的关系明确后,才可以使用UNION语法。
- 表名,列名大小写敏感。
- 没有*、#、-- 。
- 没有延时函数。
所以HQL注入利用要比SQL注入苦难得多。从代码审计的角度和普通SQL注入是一致的:
拼接会导致注入漏洞:

可以使用占位符和具名参数来防止SQL语句,其本质都是预编译。
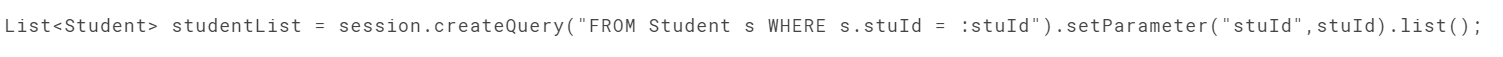

Hibernate在使用过程中有很多不足:
- 全表映射不灵活,更新时需要发送所有字段,影响程序运行效率。
- 对复杂查询的支持很差。
- 对存储过程的支持很差。
- HQL性能较差,无法根据SQL进行优化。
在审计Hibernate相关注入时,可以通过全局搜索createQuery来快速定位SQL操作的位置。
2 JPA
JPA全称为Java Persistence API,是Java EE提供的一种数据持久化的规范,允许开发者通过XML或注解的方式,将某个对象,持久化到数据库中。
主要包括三方面内容:
1.ORM映射元数据,通过XML或注解,描述对象和数据表之间的对应关系。框架便可以自动将对象中的数据保存到数据库中。
常见的注解有:@Entity、@Table、@Column、@Transient
2.数据操作API,内置接口,方便对某个数据表执行CRUD操作,节省开发者编写SQL的时间。
常见的方法有:entityManager.merge(T t);
3.JPQL, 提供一种面向对象而不是面向数据库的查询语言,将程序和数据库、SQL解耦合。
JPA是一套规范,Hibernate实现了这一JPA规范。
在Spring框架中,提供了简易版的JPA实现——spirng data jpa。按照约定好的方法命名规则写dao层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作。同时提供了很多除了CRUD之外的功能,如分页、排序、复杂查询等等。使用起来更简单,但底层仍然在使用Hibernate的JPA实现。
和HQL注入一样,如果使用拼接的方式,将用户可控的数据代入了查询语句中,就会导致SQL注入。
安全的查询应该使用预编译技术。
Spring Data JPA的预编译写法为:
String getUser = "SELECT username FROM users WHERE id = ?"; Query query = em.createNativeQuery(getUser); query.setParameter(1, id); String username = query.getResultList();
小贴士:其实Hibernate的出现日期比JPA规范要早,Hibernate逐渐成熟之后,JavaEE的开发团队,邀请Hibernate核心开发人员一起制定了JPA规范。之后Spring Data JPA按照规范做了进一步优化。除此之外,JPA规范的实现有很多产品,比如Eclipse的TopLink(OracleLink)。
六 总结
经过上面的介绍,尤其是围绕Mybatis易错点的讨论,我们可以得到以下结论:
- 持久层组件种类繁多。
- 开发者对工具使用的错误理解,是漏洞出现的主要原因。
- 由于自动生成插件的动态特性,自动化发现SQL漏洞不能简单地使用${}来寻找。必须要根据全局的持久层组件特性,来做详细的匹配规则。