zip 是一种常见的归档格式,本文讲解 Go 如何操作 zip。
首先看看 zip 文件是如何工作的。以一个小文件为例:(类 Unix 系统下)
$ cat hello.text Hello!
执行 zip 命令进行归档:
$ zip test.zip hello.text adding: hello.text (stored 0%) $ ls -lah test.zip -rw-r--r-- 1 phil phil 177 Nov 23 23:04 test.zip
一个 6 字节的文本文件变成了一个 177 字节的 zip 文件。这并不大,解析 177 个字节听起来不可能太复杂!
对 zip 文件执行 hexdump:
$ hexdump -C test.zip 00000000 50 4b 03 04 0a 00 00 00 00 00 8a b8 77 53 9e d8 |PK..........wS..| 00000010 42 b0 07 00 00 00 07 00 00 00 0a 00 1c 00 68 65 |B.............he| 00000020 6c 6c 6f 2e 74 65 78 74 55 54 09 00 03 74 73 9d |llo.textUT...ts.| 00000030 61 74 73 9d 61 75 78 0b 00 01 04 eb 03 00 00 04 |ats.aux.........| 00000040 eb 03 00 00 48 65 6c 6c 6f 21 0a 50 4b 01 02 1e |....Hello!.PK...| 00000050 03 0a 00 00 00 00 00 8a b8 77 53 9e d8 42 b0 07 |.........wS..B..| 00000060 00 00 00 07 00 00 00 0a 00 18 00 00 00 00 00 01 |................| 00000070 00 00 00 a4 81 00 00 00 00 68 65 6c 6c 6f 2e 74 |.........hello.t| 00000080 65 78 74 55 54 05 00 03 74 73 9d 61 75 78 0b 00 |extUT...ts.aux..| 00000090 01 04 eb 03 00 00 04 eb 03 00 00 50 4b 05 06 00 |...........PK...| 000000a0 00 00 00 01 00 01 00 50 00 00 00 4b 00 00 00 00 |.......P...K....| 000000b0 00 |.| 000000b1
从中我们可以看到文件名和文件内容。
01 结构
我们来看看这里[1]定义的 zip 结构 。根据第 4.3.6 节,看起来文件元数据后跟文件内容一个接一个地存储,最后一块是 “central directory” 元数据。
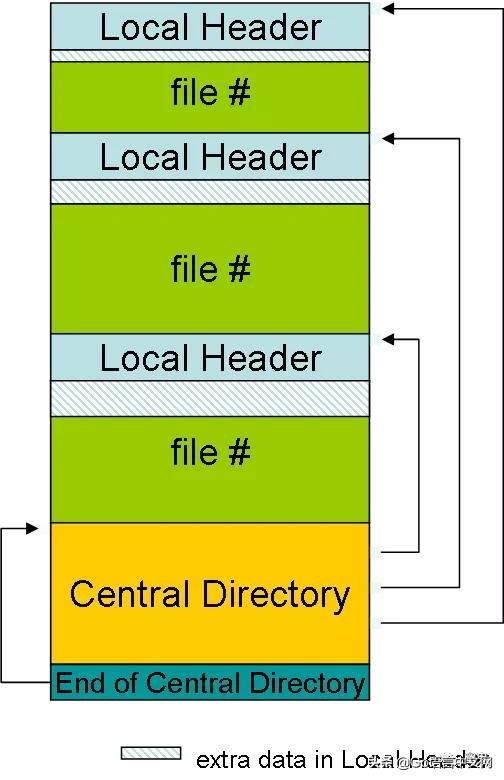
zip format header
图片来源:https://www.codeproject.com/Articles/8688/Extracting-files-from-a-remote-ZIP-archive
本地 header 元数据如下所示:
字段大小local file header signature4 bytesversion needed to extract2 bytesgeneral purpose bit flag2 bytescompression method2 byteslast mod file time2 byteslast mod file date2 bytescrc-324 bytescompressed size4 bytesuncompressed size4 bytesfile name length2 bytesextra field length2 bytesfile name可变extra field可变
在一个有效 zip 文件中,header 签名是一个整数 (0x04034b50 )。我们将忽略版本、通用 flag 和校验和。可以是没有压缩(用 0 表示),也可以是使用 DEFLATE 方法解压缩(用 8 表示)。
最后修改时间和日期是 MSDOS 风格的日期/时间格式。
我们粗略地将其翻译为 Go 代码:
package main
import (
"os"
"bytes"
"compress/flate"
"io/ioutil"
"encoding/binary"
"time"
"fmt"
)
type compression uint8
const (
noCompression compression = iota
deflateCompression
)
type localFileHeader struct {
signature uint32
version uint16
bitFlag uint16
compression compression
lastModified time.Time
crc32 uint32
compressedSize uint32
uncompressedSize uint32
fileName string
extraField []byte
fileContents string
}
02 main 函数实现
我们的入口点将读取一个 zip 文件并遍历该文件,直到我们无法解析 zip 文件条目。
func main() {
f, err := ioutil.ReadFile(os.Args[1])
if err != nil {
panic(err)
}
end := 0
for end < len(f) {
var err error
var lfh *localFileHeader
var next int
lfh, next, err = parseLocalFileHeader(f, end)
if err == errNotZip && end > 0 {
break
}
if err != nil {
panic(err)
}
end = next
fmt.Println(lfh.lastModified, lfh.fileName, lfh.fileContents)
}
}
03 文件
对于每个文件,如果前四个字节不是魔术 zip 签名(即 0x04034b50),则报错。
var errNotZip = fmt.Errorf("Not a zip file")
func parseLocalFileHeader(bs []byte, start int) (*localFileHeader, int, error) {
signature, i, err := readUint32(bs, start)
if signature != 0x04034b50 {
return nil, 0, errNotZip
}
if err != nil {
return nil, 0, err
}
基本模式是读取辅助函数将获取一个偏移量并返回一个 Go 值和一个新的偏移量。读取辅助函数将进行边界检查。
遵循相同的模式直到结构体的末尾:
version, i, err := readUint16(bs, i)
if err != nil {
return nil, 0, err
}
bitFlag, i, err := readUint16(bs, i)
if err != nil {
return nil, 0, err
}
compression := noCompression
compressionRaw, i, err := readUint16(bs, i)
if err != nil {
return nil, 0, err
}
if compressionRaw == 8 {
compression = deflateCompression
}
lmTime, i, err := readUint16(bs, i)
if err != nil {
return nil, 0, err
}
lmDate, i, err := readUint16(bs, i)
if err != nil {
return nil, 0, err
}
lastModified := msdosTimeToGoTime(lmDate, lmTime)
crc32, i, err := readUint32(bs, i)
if err != nil {
return nil, 0, err
}
compressedSize, i, err := readUint32(bs, i)
if err != nil {
return nil, 0, err
}
uncompressedSize, i, err := readUint32(bs, i)
if err != nil {
return nil, 0, err
}
fileNameLength, i, err := readUint16(bs, i)
if err != nil {
return nil, 0, err
}
extraFieldLength, i, err := readUint16(bs, i)
if err != nil {
return nil, 0, err
}
fileName, i, err := readString(bs, i, int(fileNameLength))
if err != nil {
return nil, 0, err
}
extraField, i, err := readBytes(bs, i, int(extraFieldLength))
if err != nil {
return nil, 0, err
}
现在,如果文件内容未压缩,我们只需复制文件头后的字节即可。如果文件内容被压缩,我们将使用 Go 的内置 DEFLATE 支持来解压缩文件头之后的字节。
var fileContents string
if compression == noCompression {
fileContents, i, err = readString(bs, i, int(uncompressedSize))
if err != nil {
return nil, 0, err
}
} else {
end := i + int(compressedSize)
if end > len(bs) {
return nil, 0, errOverranBuffer
}
flateReader := flate.NewReader(bytes.NewReader(bs[i:end]))
defer flateReader.Close()
read, err := ioutil.ReadAll(flateReader)
if err != nil {
return nil, 0, err
}
fileContents = string(read)
i = end
}
并返回填充好的结构体实例:
return &localFileHeader{
signature: signature,
version: version,
bitFlag: bitFlag,
compression: compression,
lastModified: lastModified,
crc32: crc32,
compressedSize: compressedSize,
uncompressedSize: uncompressedSize,
fileName: fileName,
extraField: extraField,
fileContents: fileContents,
}, i, nil
}
04 读取辅助函数
现在我们只定义那些带有边界检查的读取辅助函数,使用 Go 的内置库来处理二进制编码。
var errOverranBuffer = fmt.Errorf("Overran buffer")
func readUint32(bs []byte, offset int) (uint32, int, error) {
end := offset + 4
if end > len(bs) {
return 0, 0, errOverranBuffer
}
return binary.LittleEndian.Uint32(bs[offset:end]), end, nil
}
func readUint16(bs []byte, offset int) (uint16, int, error) {
end := offset+2
if end > len(bs) {
return 0, 0, errOverranBuffer
}
return binary.LittleEndian.Uint16(bs[offset:end]), end, nil
}
并且基本上只对获取的字节和字符串进行边界检查。
func readBytes(bs []byte, offset int, n int) ([]byte, int, error) {
end := offset + n
if end > len(bs) {
return nil, 0, errOverranBuffer
}
return bs[offset:offset+n], end, nil
}
func readString(bs []byte, offset int, n int) (string, int, error) {
read, end, err := readBytes(bs, offset, n)
return string(read), end, err
}
05 MSDOS 时间
我猜在创建 zip 时,MSDOS 时间格式很流行。但它在今天并不流行,所以花了一些时间才最终用一些代码(模仿 C 语言)找到对该格式的解释[2]。
func msdosTimeToGoTime(d uint16, t uint16) time.Time {
seconds := int((t & 0x1F) * 2)
minutes := int((t >> 5) & 0x3F)
hours := int(t >> 11)
day := int(d & 0x1F)
month := time.Month((d >> 5) & 0x0F)
year := int((d >> 9) & 0x7F) + 1980
return time.Date(year, month, day, hours, minutes, seconds, 0, time.Local)
}
06 测试
运行:
$ go build $ ./gozip test.zip 2021-11-23 23:04:20 +0000 UTC hello.text Hello!
这看起来不错!现在让我们尝试压缩多个文件。
$ cat bye.text Au revoir! $ rm test.zip $ zip test.zip *.text adding: bye.text (stored 0%) adding: hello.text (stored 0%) $ ./gozip test.zip 2021-11-24 03:40:00 +0000 UTC bye.text Au revoir! 2021-11-23 23:04:20 +0000 UTC hello.text Hello!
一切正常。
07 总结
实际上,还有许多标准需要处理(例如目录)和许多常见的扩展,本文没有涉及。