前言
在自然语言处理中,我们经常需要判定两个东西是否相似。
比如,在微博的热点话题推荐那里,我们需要比较微博之间的相似度,让相似度高的微博聚集在一起形成一个簇,提出一个主题。
在问答系统中,比如说人工客服,我们需要提前准备好问题和一些答案,让用户输入的问题与题库中的问题进行相似度的比较,最后输出答案。
在推荐系统中,我们需要提取一个用户的所有物品,在根据这个物品找到对应的用户群,比较两个用户之间的相似性,在进行相应的推荐(协同过滤)。
在对语料进行预处理的时候,我们需要给予文本的相似度,把相似度高的重复主题过滤掉。
总之,相似度是一种非常有用的工具,可以帮助我们解决很多问题。

任务目标
一般来说,是比较两个物体(商品,文本)之间的相似度。这里的相似度是一个抽象的值,它可以抽象成估计的百分比。
在推荐工程中,计算相似度是为了给用户推送一定量的物品。即把所有的相似度排序,然后选出最高的那几个物品。
人是很容易判断出物品的相似度的,人们会在心里有一个考量。那么程序如何判断呢?
如果是文本分析,它首先就要用到分词技术,然后去掉不必要的词(语气词,连接词)。然后对词给一个抽象的量表示权重,最后在用一些方法去统计出整体的相似度。
如果是其他的,可能首先也需要进行数据清洗的工作,留下那些关键的能够表示物体特征的部分,对这些部分定权值,再去估计整体。
-
相似度计算关键组件
相似度计算方法有2个关键组件:
-
表示模型
-
度量方法
前者负责将物体表示为计算机可以计算的数值向量,也就是提供特征。
后者负责基于前面得到的数值向量计算物体之间的相似度。
-
距离的度量方式
欧几里得距离

使用python计算欧式距离:
distance = numpy.linalg.norm(vec1 - vec2)
相似度为:
similarity = 1.0/(1.0 + np.linalg.norm(dataA - dataB))
-
余弦距离
余弦距离的计算方式:
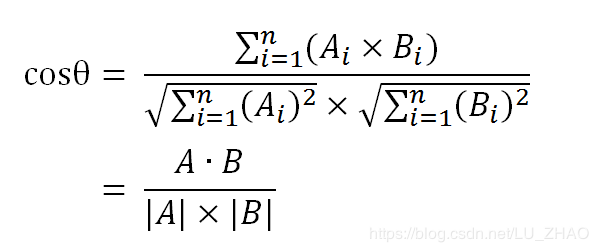
与欧氏距离的区别:
-
欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如使用用户行为指标分析用户价值的相似度或差异。
-
余弦距离更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦距离对绝对数值不敏感)
-
Jacard相似度
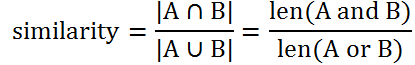
distance = 1 / similarity
思想非常简单,两个集合共有的元素越多,二者越相似。
-
汉明距离
两个字码中不同位值的数目称为汉明距离。
-
Hamming distance = 0 (ai = bi)
-
Hamming distance = 1 (ai != bi)
最后统计相加。
-
最小编辑距离
最小编辑距离是一种经典的距离计算方法,用来度量字符串之间的差异。它认为,将字符串A不断修改(增删改)、直至成为字符串B,所需要的修改次数代表了字符串A和B的差异大小。当然了,将A修改为B的方案非常多,选哪一种呢?我们可以用动态规划找到修改次数最小的方案,然后用对应的次数来表示A和B的距离。