一、Spring部分
1、Spring的运行流程
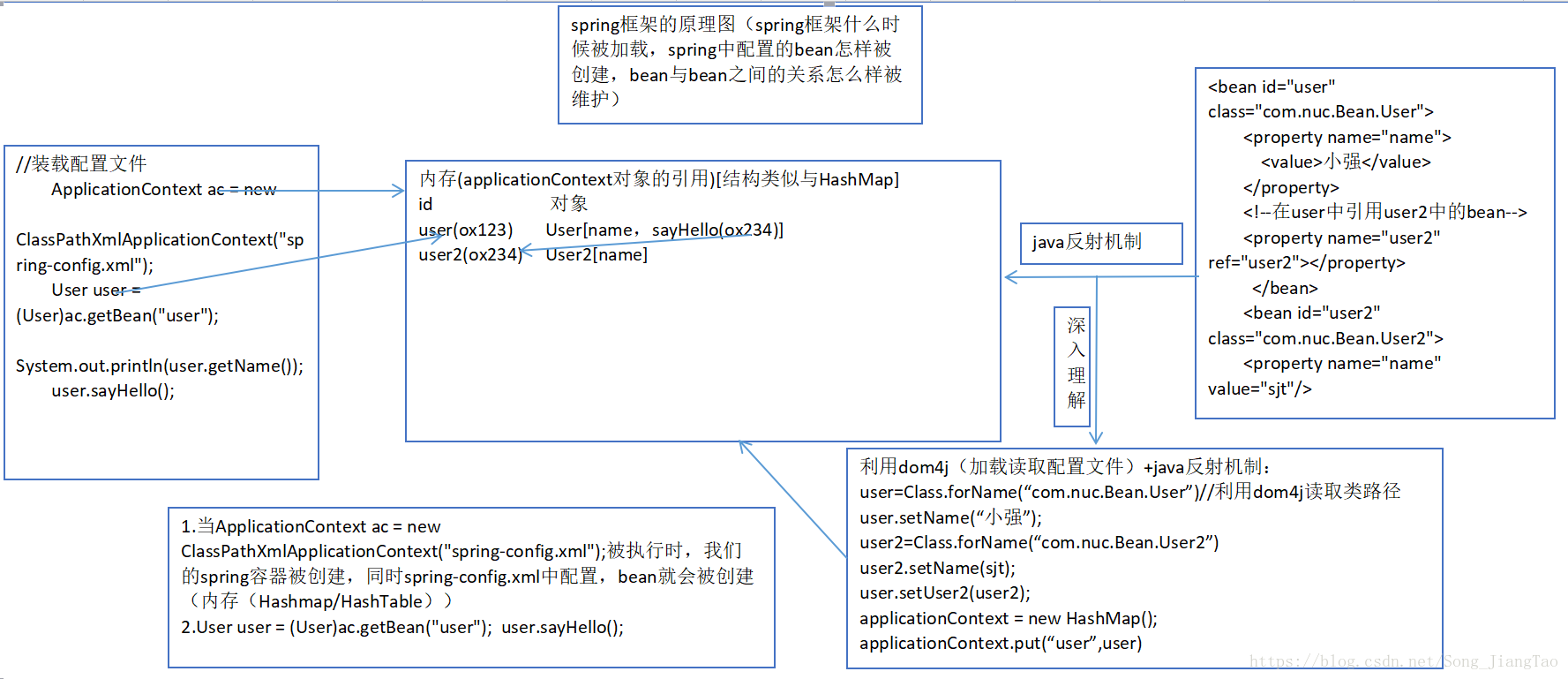
第一步:加载配置文件ApplicationContext ac = new ClassPathXmlApplicationContext("beans.xml");,ApplicationContext接口,它由BeanFactory接口派生而来,因而提供了BeanFactory所有的功能。配置文件中的bean的信息是被加载在HashMap中的,一个bean通常包括,id,class,property等,bean的id对应HashMap中的key,value呢就是bean
具体如何加载?源码如下:
if (beanProperty.element("map") != null){
Map<String, Object> propertiesMap = new HashMap<String, Object>();
Element propertiesListMap = (Element)beanProperty.elements().get(0);
Iterator<?> propertiesIterator = propertiesListMap .elements().iterator();
while (propertiesIterator.hasNext()) {
Element vet = (Element) propertiesIterator.next();
if(vet.getName().equals("entry")) {
String key = vet.attributeValue("key");
Iterator<?> valuesIterator = vet.elements() .iterator();
while (valuesIterator.hasNext()) {
Element value = (Element) valuesIterator.next();
if (value.getName().equals("value")){
propertiesMap.put(key, value.getText());
}
if (value.getName().equals("ref")) {
propertiesMap.put(key, new String[]{
value.attributeValue("bean")
});
}
}
}
}
bean.getProperties().put(name, propertiesMap);
//看完反正我是默默放弃了。。。
}
12345678910111213141516171819202122232425
第二步:调用getBean方法,getBean是用来获取applicationContext.xml文件里bean的,()写的是bean的id。一般情况都会强转成我们对应的业务层(接口)。例如SpringService springService =(SpringService)ac.getBean("Service");
第三步:这样我们就可以调用业务层(接口实现)的方法。
具体如下:
Java反射博大精深,我也不很懂,具体请查看Java基础之—反射
那么bean中的东西到底是怎么注入进去的?**简单来讲,就是在实例化一个bean时,实际上就实例化了类,它通过**反射调用类中set方法将事先保存在HashMap中的类属性注入到类中。这样就回到了我们Java最原始的地方,对象.方法,对象.属性
2、Spring的原理
- 什么是spring? spring是一个容器框架,它可以接管web层,业务层,dao层,持久层的各个组件,并且可以配置各种bean, 并可以维护bean与bean的关系,当我们需要使用某个bean的时候,我们可以直接getBean(id),使用即可
- Spring目的:就是让对象与对象(模块与模块)之间的关系没有通过代码来关联,都是通过配置类说明管理的(Spring根据这些配置 内部通过反射去动态的组装对象) ,Spring是一个容器,凡是在容器里的对象才会有Spring所提供的这些服务和功能。
-
层次框架图: 说明: web层: struts充当web层,接管jsp,action,表单,主要体现出mvc的数据输入,数据的处理,数据的显示分离。
model层: model层在概念上可以理解为包含了业务层,dao层,持久层,需要注意的是,一个项目中,不一定每一个层次都有。
持久层: 体现oop,主要解决关系模型和对象模型之间的*阻抗*
3、Spring的核心技术
- IOC
ioc(inverse of control)控制反转: 所谓反转就是把创建对象(bean)和维护对象(bean)之间的关系的权利从程序转移到spring的容器(spring-config.xml)
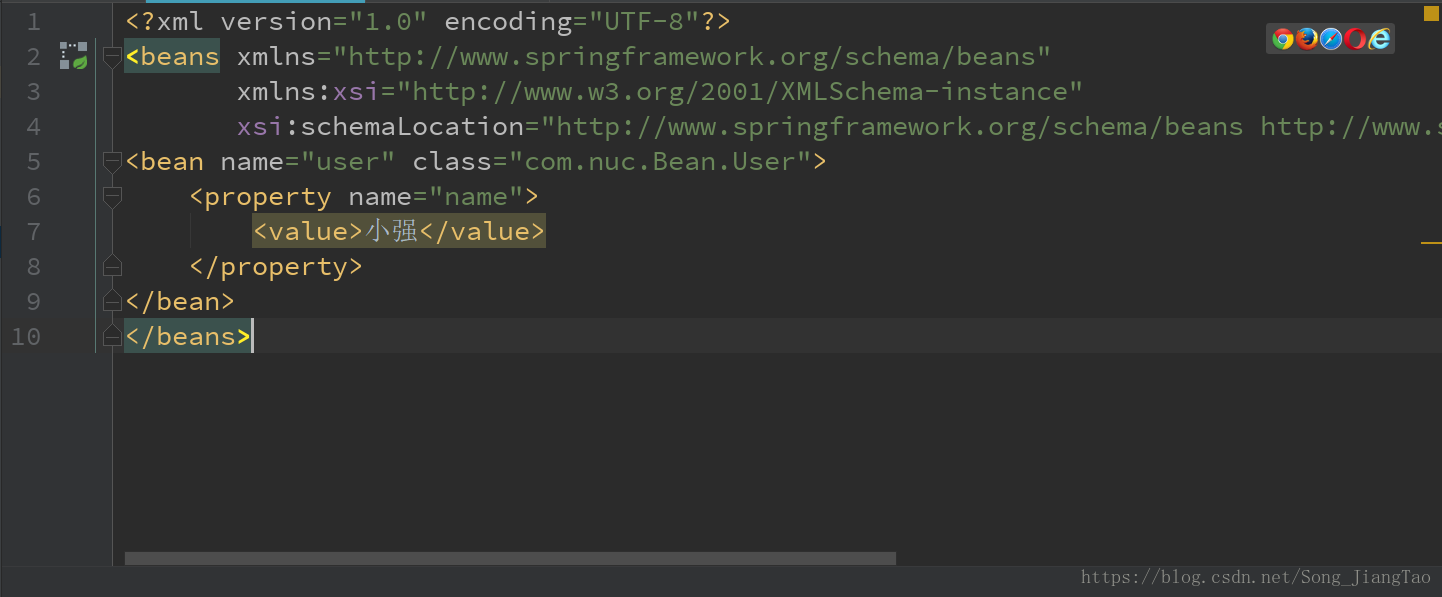
说明:<bean></bean>这对标签元素的作用:当我们加载spring框架时,spring就会自动创建一个bean对象,并放入内存相当于我们常规的new一个对象,而<property></property>中的value则是实现了“对象.set方法”,这里也体现了注入了概念
- DI
di(dependency injection)依赖注入: 实际上di和ioc是同一个概念,spring的设计者,认为di更准确的表示spring的核心
spring提倡接口编程,在配合di技术就可以达到层与层解耦的目的,为什么呢?因为层与层之间的关联,由框架帮我们做了,这样代码之间的耦合度降低,代码的复用性提高
接口编程的好处请访问(https://blog.csdn.net/Song_JiangTao/article/details/82389905)
- AOP aspect oriented programming(面向切面编程) 核心:在不增加代码的基础上,还增加新功能 理解: 面向切面:其实是,把一些公共的“东西”拿出来,比如说,事务,安全,日志,这些方面,如果你用的到,你就引入。 也就是说:当你需要在执行一个操作(方法)之前想做一些事情(比如,开启事务,记录日志等等),那你就用before,如果想在操作之后做点事情(比如,关闭一些连接等等),那你就用after。其他类似
4、Spring整体架构图
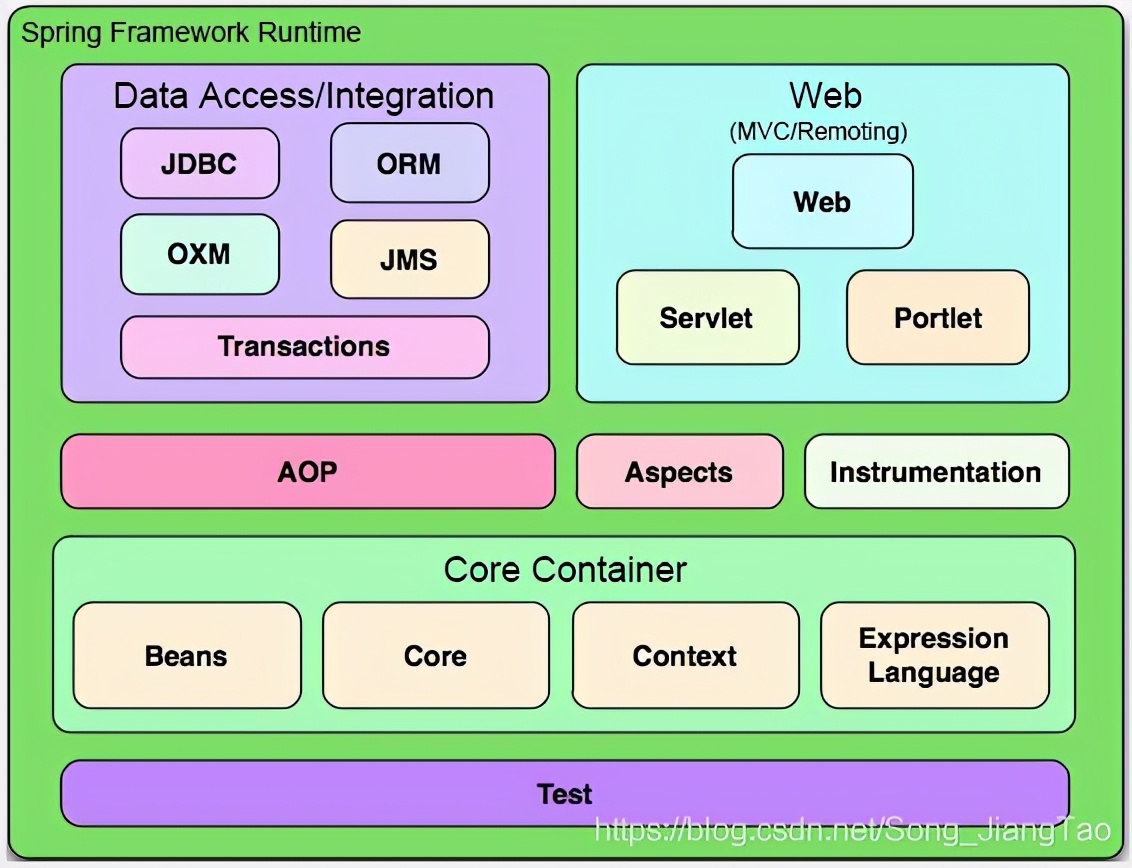
1、core container(核心容器)
核心容器包含了core,beans,context和expression language四个模块,core和beans模块是框架的基础部分,提供IOC和依赖注入特性。这里的基础概念是BeanFactory,它提供对Factory模式的经典实现来消除对程序性单例模式的需要,并真正地允许你从程序逻辑中分离出依赖关系和配置。
- core模块主要包含了spring框架基本的黑犀牛工具类,spring的其他组建都要用到这个包里的类,core模块是其他组件的基本核心。当然你也可以在自己应用系统中使用这些工具类。
- beans模块是所有应用都要用到的,它包含访问配置文件,创建和管理bean以及进行ioc,di操作相关的所有类
- context模块构建与core和beans模块基础之上,提供了一种类似于JNDI注册器的框架式的对象访问方法。context模块继承了beans的特性,为spring核心提供了大量扩展,添加了对国际化(例如资源绑定)、事件传播、资源加载和对context的透明创建的支持。context模块同事也支持j2ee的一些特性,例如EJB,JMX和基础的远程处理,applicationContext接口是context模块的关键。
- ExpressionLanguage模块提供了强大的表达式语言,用于在运行时查询和操纵对象。他是jsp2.1规范中定义的unifed expression language的扩展。该语言支持设置/获取属性的值,属性的分配,方法的调用 ,访问数组上下文,容器和索引器,逻辑和算数运算符,命名变量以及从spring的ioc容器中根据名称检索对象。它也支持list投影,选择和一般的list聚合
2、Date Access/Integration
Date Access/Integration层包含JDBC,ORM,OXM,JMS和Transaction模块
- jdbc模块提供了一个jdbc抽象层,他可以消除冗长的jdbc编码和解析数据厂商特有的错误代码。这个模块包含了spring对jdbc数据访问进行封装的所有类。
- orm模块为流行的对象-关系映射API,如JPA,JDO,Hibernate,iBatis等,提供了一个交互层。利用ORM封装包,可以混合使用所有spring提供的特性进行O/R映射,如前边提到的简单声明性事务管理。spring框架插入了若干个ORM框架 ,从而提供了ORM的对象关系工具,其中包括JDO,hibernate和iBatisSQl Map。所有这些都遵从spring的通用事务和DAO异常层次结构。
- OXM模块提供了一个对Object/XML映射实现的抽象层,Object/XML映射实现包括JAXB,Castor,XMLBeans,JiBX和XStream。
- JMS(java massage service)模块主要包含了一些制造和消费消息的特性
- Transaction模块支持编程和声明性的事务管理,这些事务类必须实现特地的接口。并且对多有的POJO都适用
3、web
web上下文模块建立在应用程序上下文模块之上,为基于web的应用程序提供了上下文。所以,spring框架支持与Jakarta struts的集成。web模块还简化了处理大部分请求以及将请求参数绑定到域对象的工作。web层包含了web,web-servlet,web-Struts 和web-porlet
- web模块,提供了基础的面向web的集成特性。例如:多文件上传,使用servlet listeners初始化 Ioc容器已经一个面向web的应用上下文。它还包含spring远程支持中的web的相关部分。
- web-servlet模块web.servlet.jar:该模块包含spring的model-view-controller(mvc)实现。spring的mbc框架使得模型范围内的代码和webforms之间能够清楚地分离出来。并与spring框架的其他特性集成在一起。
- web-Struts模块,该模块提供了对struts的支持,使得类在spring应用中能够与一个典型的struts web层集成在一起。注意,该支持在spring3.0中已被弃用。
- web-portlet模块,提供了用于portlet环境和web-servlet模块的MVC的实现。
4、AOP
aop模块提供了一个符合aop联盟标准的面向切面编程的实现,它让你可以定义例如方法拦截器和切点,从而将逻辑代码分开,降低它们之间的耦合性。利用source-level的元数据功能,还可以将各种行为信息合并到你的代码中,这有点像.Net技术中的attribute概念
通过配置管理特性,springAop模块直接将面向界面的编程功能集成到了spring框架中,所以可以很容易地使用spring框架管理的任何对象支持aop,springAop模块为基于spring的应用程序中的对象提供了事务管理服务。通过使用springAop,不用历来EJB组件,就可以将声明性事务管理集成到应用程序中。
- Aspects模块提供了AspectJ的集成支持。
- Instrumentation模块提供了class Instrumentation支持和classloader实现,使用可以再特定的应用服务器上使用。
5、Test
test模块支持使用JUnit和TestNG对spring组件进行测试。
二、Spring MVC部分
1、Spring MVC的运行流程
- springMVC框架 框架执行流程(面试必问) 1、用户发送请求至前端控制器DispatcherServlet2、DispatcherServlet收到请求调用HandlerMapping处理器映射器。3、处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。4、DispatcherServlet通过HandlerAdapter处理器适配器调用处理器5、执行处理器(Controller,也叫后端控制器)。6、Controller执行完成返回ModelAndView7、HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet8、DispatcherServlet将ModelAndView传给ViewResolver视图解析器9、ViewResolver解析后返回具体View10、DispatcherServlet对View进行渲染视图(即将模型数据填充至视图中)。11、DispatcherServlet响应用户
2、Spring MVC的原理
- 1、什么是SpringMVC?
- springmvc是spring框架的一个模块,springmvc和spring无需通过中间整合层进行整合。
- springmvc是一个基于mvc的web框架。
- mvc mvc在b/s系统 下的应用: 前端控制器DispatcherServlet(不需要程序员开发) 作用接收请求,响应结果,相当于转发器,中央处理器。有了DispatcherServlet减少了其它组件之间的耦合度。 处理器映射器HandlerMapping(不需要程序员开发) 作用:根据请求的url查找Handler 处理器适配器HandlerAdapter 作用:按照特定规则(HandlerAdapter要求的规则)去执行Handler 处理器Handler (需要程序员开发) 。注意:编写Handler时按照HandlerAdapter的要求去做,这样适配器才可以去正确执行Handler 视图解析器View resolver(不需要程序员开发) 作用:进行视图解析,根据逻辑视图名解析成真正的视图(view) 视图View (需要程序员开发) View是一个接口,实现类支持不同的View类型(jsp、freemarker、pdf…)
- struts2与springMVC的区别?
1、Struts2是类级别的拦截,一个类对应一个request 上下文, SpringMVC是方法级别的拦截,一个方法对应一个request上下文,而方法同时又跟一个url对应,,所以说从架构本身上SpringMVC就容易实现restful url,而struts2的架构实现起来要费劲,因为Struts2中Action的一个方法可以对应一个url ,而其类属性却被所有方法共享,这也就无法用注解或其他方式标识其所属方法了。
2、由上边原因, SpringMVC的方法之间基本上独立的,**独享request response数据,*请求数据通过参数获取,处理结果通过ModelMap交回给框架,方法之间不共享变量,而Struts2搞的就比较乱,虽然方法之间也是独立的,但其*所有Action变量是共享的,这不会影响程序运行,却给我们编码读程序时带来麻烦,每次来了请求就创建一个Action ,一个Action对象对应一个request 上下文。
3、由于Struts2需要针对每个request进行封装,把request , session等servlet生命周期的变量封装成一个一 个Map ,供给每个Action使用,并保证线程安全,所以在原则上,是比较耗费内存的。
4、拦截器实现机制上, Struts2有以自己的interceptor机制, SpringMVC用的是独立的AOP方式,这样导致Struts2的配置文件量还是比SpringMVC大。
5、SpringMVC的入口是servlet ,而Struts2是filter (这里要指出, filter和servlet是不同的。以前认为filter是servlet的一种特殊),这就导致 了二者的机制不同,这里就牵涉到servlet和filter的区别了。
6、SpringMVC集成了Ajax ,使用非常方便,只需一个注解@ResponseBody就可以实现,然后直接返回响应文本即可,而Struts2拦截器集成了Ajax ,在Action中处理时一般必须安装插件或者自己写代码集成进去,使用起来也相对不方便。
7、**SpringMVC验证支持JSR303 ,*处理起来相对更加灵活方便,而*Struts2验证比较繁琐,感觉太烦乱。
8、Spring MVC和Spring是无缝的。从这个项目的管理和安全上也比Struts2高(当然Struts2也可以通过不同的目录结构和相关配置做到SpringMVC-样的效果,但是需要xml配置的地方不少)。
9、设计思想上, Struts2更加符合0OP的编程思想,SpringMVC就比较谨慎,在servlet上扩展。
10、SpringMVC开发效率和性能高于Struts2。
11、SpringMVC可以认为已经100%零配置。
3、Spring MVC的核心技术
- 注解开发(@Controller,@RequestMapping,@ResponseBody。。。。)还有Spring的诸多注解,这两者是不需要整合的~
- 传参,接参(request)
- 基本配置
- 文件上传与下载。Spring MVC中文件上传需要添加Apache Commons FileUpload相关的jar包;基于该jar, Spring中提供了MultipartResolver实现类: CommonsMultipartResolver.
- 拦截器其实最核心的还是SpringMVC的执行流程,各个点的作用得搞清楚。
三、Mybatis部分
1、Mybatis的运行流程
- Mybatis运行流程图:
第一步:配置文件mybatis.xml,大体如下,
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 引入外部文件
resource:引入项目中配置文件
url:引入网络中或者路径文件
-->
<properties resource="jdbc.properties"/>
<settings>
<!--<setting name="mapUnderscoreToCamelCase" value="true" />-->
<setting name="lazyLoadingEnabled" value="true" />
<setting name="aggressiveLazyLoading" value="false" />
<setting name="cacheEnabled" value="true"/>
</settings>
<typeAliases>
<package name="com.nuc.entity"></package>
</typeAliases>
<!-- - - - - - - 数据库环境配置- - - - - - - - - -->
<environments default="environments">
<environment id="environments">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driverClass}"/>
<property name="url" value="${jdbc.jdbcUrl}"/>
<property name="username" value="${jdbc.user}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
<!-- - - - - - - -映射文件路径- - - - - - -->
<mappers>
<!--自动扫描包下的映射文件,要求:同名,同目录-->
<package name="com.nuc.mapper" />
</mappers>
</configuration>
第二步:加载我们的xml文件 第三步:创建SqlSessionFactoryBuilder 第四步:创建SqlSessionFactory 第五步:调用openSession(),开启sqlSession 第六步:getMapper()来获取我们的mapper(接口),mapper对应的映射文件,在加载mybatis.xml时就会加载 第七步:使用我们自己的mapper和它对应的xml来完成我们和数据库交互。即增删改查。 第八步:提交session,关闭session。
代码如下:
String resource = "mybatis-config.xml"; SqlSession sqlSession = null; InputStream inputStream = Resources.getResourceAsStream(resource);//读取mybatis配置文件 //SqlSessionFactoryBuilder这个类的作用就是为了创建SqlSessionFactory的 SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder(); SqlSessionFactory factory = builder.build(inputStream); /** * factory.openSession(); //需手动提交事务 * factory.openSession(true); //系统自动提交事务 */ sqlSession = factory.openSession(); CustomerMapper mapper = sqlSession.getMapper(CustomerMapper.class); //增删改查的操作 sqlSession.commit();//如果没有提交,数据库的数据不会改变 sqlSession.close(); 12345678910111213141516
需要注意的是,sqlSession也自带一些数据交互的操作
2、Mybatis的原理
- 什么是Mybatis? mybatis专注sql本身,需要程序员自己编写sql语句,sql修改、优化比较方便。mybatis是一个不完全 的ORM框架,虽然程序员自己写sql,mybatis 也可以实现映射(输入映射、输出映射)。mybatis是一个持久层的框架,是apache下的顶级项目。mybatis托管到goolecode下,后来托管到github下:mybatis Github地址mybatis让程序将主要精力放在sql上,通过mybatis提供的映射方式,自由灵活生成(半自动化,大部分需要程序员编写sql)满足需要sql语句。mybatis可以将向 preparedStatement中的输入参数自动进行输入映射,将查询结果集灵活映射成java对象。(输出映射)
- mybatis底层实现 mybatis底层还是采用原生jdbc来对数据库进行操作的,只是通过 SqlSessionFactory,SqlSession Executor,StatementHandler,ParameterHandler,ResultHandler和TypeHandler等几个处理器封装了这些过程
- 对原生态jdbc程序(单独使用jdbc开发)问题总结: 1、数据库连接,使用时创建,不使用就关闭,对数据库进行频繁连接开启和关闭,造成数据库资源的浪费 解决:使用数据库连接池管理数据库连接 2、将sql 语句硬编码到Java代码中,如果sql语句修改,需要对java代码重新编译,不利于系统维护 解决:将sql语句设置在xml配置文件中,即使sql变化,也无需重新编译 3、向preparedStatement中设置参数,对占位符位置和设置参数值,硬编码到Java文件中,不利于系统维护 解决:将sql语句及占位符,参数全部配置在xml文件中 4、从resutSet中遍历结果集数据时,存在硬编码,将获取表的字段进行硬编码,不利于系统维护。 解决:将查询的结果集,自动映射成java对象
- mybatis工作原理 mybatis通过配置文件创建sqlsessionFactory,sqlsessionFactory根据配置文件,配置文件来源于两个方面:一个是xml,一个是Java中的注解,获取sqlSession。SQLSession包含了执行sql语句的所有方法,可以通过SQLSession直接运行映射的sql语句,完成对数据的增删改查和事物的提交工作,用完之后关闭SQLSession。
3、Mybatis的核心技术
- Mybatis输入映射 通过parameterType指定输入参数的类型,类型可以是简单类型、hashmap、pojo的包装类型
- Mybatis输出映射 1、resultType 作用:将查询结果按照sql列名pojo属性名一致性映射到pojo中。使用resultType进行输出映射,只有查询出来的列名和pojo中的属性名一致,该列才可以映射成功。如果查询出来的列名和pojo中的属性名全部不一致,则不会创建pojo对象。只要查询出来的列名和pojo中的属性有一个一致,就会创建pojo对象如果查询出来的列名和pojo的属性名不一致,通过定义一个resultMap对列名和pojo属性名之间作一个映射关系。 2、resultMap** 使用association和collection完成一对一和一对多高级映射(对结果有特殊的映射要求)。association: 作用:将关联查询信息映射到一个pojo对象中。场合:为了方便查询关联信息可以使用association将关联订单信息映射为用户对象的pojo属性中,比如:查询订单及关联用户信息。使用resultType无法将查询结果映射到pojo对象的pojo属性中,根据对结果集查询遍历的需要选择使用resultType还是resultMap。 collection: 作用:将关联查询信息映射到一个list集合中。场合:为了方便查询遍历关联信息可以使用collection将关联信息映射到list集合中,比如:查询用户权限范围模块及模块下的菜单,可使用collection将模块映射到模块list中,将菜单列表映射到模块对象的菜单list属性中,这样的作的目的也是方便对查询结果集进行遍历查询。如果使用resultType无法将查询结果映射到list集合中。
- Mybatis的动态sql
- 什么是动态sql? mybatis核心 对sql语句进行灵活操作,通过表达式进行判断,对sql进行灵活拼接、组装。包括, where ,if,foreach,choose,when,otherwise,set,trim等标签的使用
- 数据模型分析思路 1、每张表记录的数据内容 分模块对每张表记录的内容进行熟悉,相当 于你学习系统 需求(功能)的过程 2、每张表重要的字段设置 非空字段、外键字段
- 3、数据库级别表与表之间的关系 外键关系
- 4、表与表之间的业务关系 在分析表与表之间的业务关系时一定要建立 在 某 个 业 务 意 义 基 础 上 去 分 析 。 \color{red}{在某个业务意义基础上去分析。}在某个业务意义基础上去分析。