redis有5种基本数据结构,它们是String(string)、列表(list)、hash(字典)、set(集合)和zset(有序集合),redis的所有数据结构都使用惟一的key字符串作为名称,接着,根据这个惟一的key值得到对应的值,不同的数据结构的差异就在于value的数据结构的差异
Redis基本数据类型
String
字符串常用操作
SET key value //存入字符串键值对 MSET key value [key value ...] //批量存储字符串键值对 SETNX key value //存入一个不存在的字符串键值对 GET key //获取一个字符串键值 MGET key [key ...] //批量获取字符串键值 DEL key [key ...] //删除一个键 EXPIRE key seconds //设置一个键的过期时间(秒)1234567复制代码类型:[java]
原子加减
INCR key //将key中储存的数字值加1 DECR key //将key中储存的数字值减1 INCRBY key increment //将key所储存的值加上increment DECRBY key decrement //将key所储存的值减去decrement1234复制代码类型:[java]
String应用场景
单值缓存
SET key value GET key SET user:1 value(json格式数据) MSET user:1:name A user:1:age 18 MGET user:1:name user:1:age12345复制代码类型:[java]
分布式锁
SETNX product:10001 true //返回1代表获取锁成功 SETNX product:10001 true //返回0代表获取锁失败 ... //业务操作 DEL product:10001 //执行完业务释放锁 SET product:10001 true ex 10 nx //防止程序意外终止导致死锁12345复制代码类型:[java]
计数器
INCR article:readcount:{文章id}
GET article:readcount:{文章id}12复制代码类型:[java]
Web集群session共享
spring session + redis实现session共享1复制代码类型:[java]
分布式系统全局序列号
INCRBY orderId 1000 //redis批量生成序列号提升性能1复制代码类型:[java]
List
List常用操作
LPUSH key value [value ...] //将一个或多个值value插入到key列表的表头(最左边) RPUSH key value [value ...] //将一个或多个值value插入到key列表的表尾(最右边) LPOP key //移除并返回key列表的头元素 RPOP key //移除并返回key列表的尾元素 LRANGE key start stop //返回列表key中指定区间内的元素,区间以偏移量start和stop指定 BLPOP key [key ...] timeout //从key列表表头弹出一个元素,若列表中没有元素,阻塞等待timeout秒,如果timeout=0,一直阻塞等待 BRPOP key [key ...] timeout //从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待timeout秒,如果timeout=0,一直阻塞1234567复制代码类型:[java]
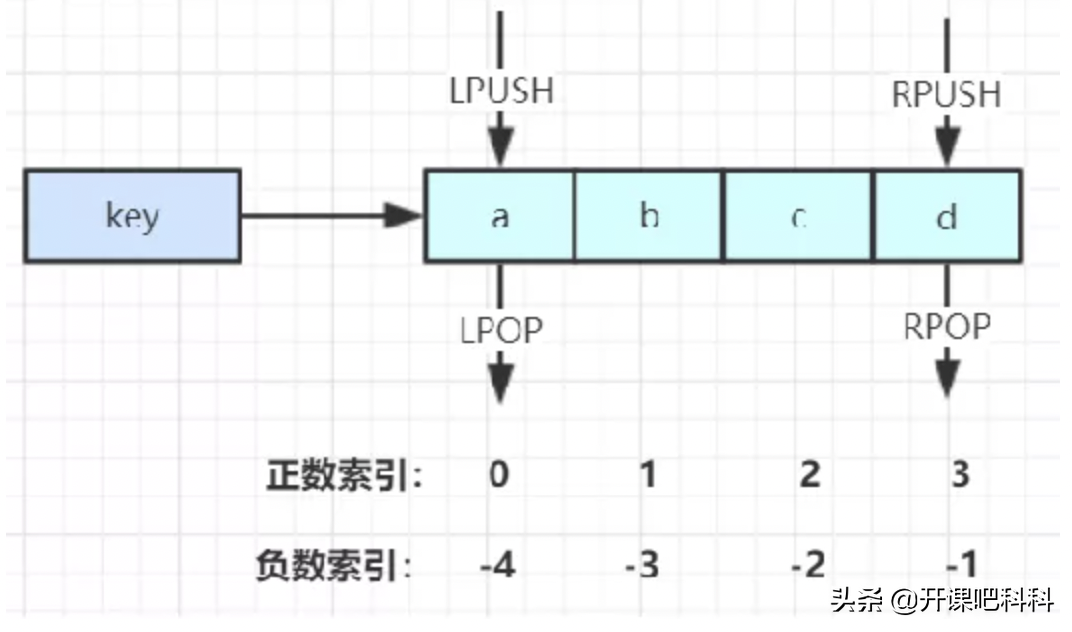
List应用场景
常用数据结构
Stack(栈) = LPUSH + LPOP
Queue(队列)= LPUSH + RPOP
Blocking MQ(阻塞队列)= LPUSH + BRPOP
微博消息和微信公众号消息
A关注了B,C
1)B发微博,消息ID为10001
LPUSH msg:{A-ID} 10001
2)C发微博,消息ID为10002
LPUSH msg:{A-ID} 10002
3)A查看最新微博消息
LRANGE msg:{A-ID} 0 41234567复制代码类型:[java]
Hash
常用操作
HSET key field value //存储一个哈希表key的键值 HSETNX key field value //存储一个不存在的哈希表key的键值 HMSET key field value [field value ...] //在一个哈希表key中存储多个键值对 HGET key field //获取哈希表key对应的field键值 HMGET key field [field ...] //批量获取哈希表key中多个field键值 HDEL key field [field ...] //删除哈希表key中的field键值 HLEN key //返回哈希表key中field的数量 HGETALL key //返回哈希表key中所有的键值 HINCRBY key field increment //为哈希表key中field键的值加上增量increment123456789复制代码类型:[java]
Hash应用场景
对象缓存
HMSET user {userId}:name A {userId}:age 18
HMSET user 1:name A 1:age 18
HMGET user 1:name 1:age123复制代码类型:[java]
电商购物车
//以用户id为key,商品id为field,商品数量为value //添加商品 //cart代表购物车,1001代表用户id,cart:1001代表用户1001的购物车 //10088代表他的购物车有一件id为10088的商品,1代表购物车的商品数量为1 hset cart:1001 10088 1 //增加数量 hincrby cart:1001 10088 1 //商品总数 hlen cart:1001 //删除商品 hdel cart:1001 10088 //获取购物车所有商品 hgetall cart:100112345678910111213复制代码类型:[java]
Hash结构优缺点
优点
1)同类数据归类整合储存,方便数据管理
2)相比string操作消耗内存与cpu更小
3)相比string储存更节省空间
缺点
1)过期功能不能使用在field上,只能用在key上
2)Redis集群架构下不适合大规模使用
Set
Set常用操作
SADD key member [member ...] //往集合key中存入元素,元素存在则忽略,若key不存在则新建 SREM key member [member ...] //从集合key中删除元素 SMEMBERS key //获取集合key中所有元素 SCARD key //获取集合key的元素个数 SISMEMBER key member //判断member元素是否存在于集合key中 SRANDMEMBER key [count] //从集合key中选出count个元素,元素不从key中删除 SPOP key [count] //从集合key中选出count个元素,元素从key中删除1234567复制代码类型:[java]
Set运算操作
SINTER key [key ...] //交集运算 SINTERSTORE destination key [key ..] //将交集结果存入新集合destination中 SUNION key [key ..] //并集运算 SUNIONSTORE destination key [key ...] //将并集结果存入新集合destination中 SDIFF key [key ...] //差集运算 SDIFFSTORE destination key [key ...] //将差集结果存入新集合destination中123456复制代码类型:[java]
Set应用场景
微信抽奖小程序
1)点击参与抽奖加入集合
SADD key {userlD}
2)查看参与抽奖所有用户
SMEMBERS key
3)抽取count名中奖者
SRANDMEMBER key [count] / SPOP key [count]123456复制代码类型:[java]
微信微博点赞,收藏,标签
1) 点赞
SADD like:{消息ID} {用户ID}
2) 取消点赞
SREM like:{消息ID} {用户ID}
3) 检查用户是否点过赞
SISMEMBER like:{消息ID} {用户ID}
4) 获取点赞的用户列表
SMEMBERS like:{消息ID}
5) 获取点赞用户数
SCARD like:{消息ID}12345678910复制代码类型:[java]
集合操作
SINTER set1 set2 set3 //{ c }
SUNION set1 set2 set3 //{ a,b,c,d,e }
SDIFF set1 set2 set3 //{ a }123复制代码类型:[java]
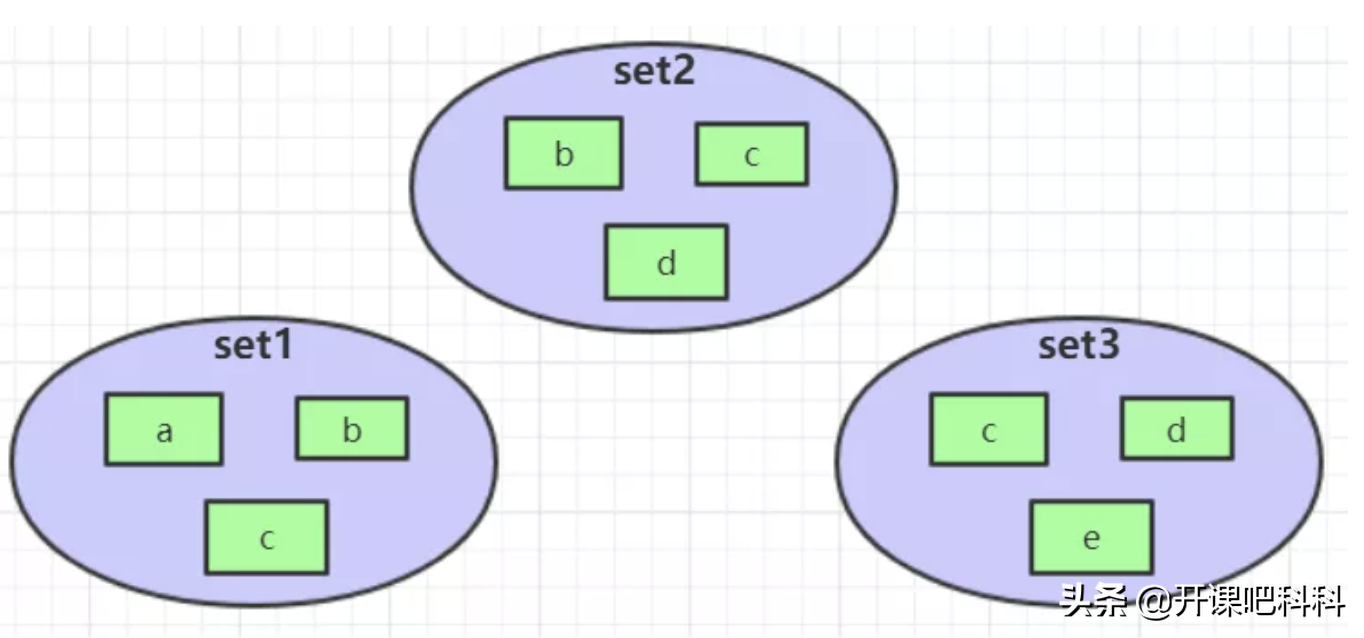
集合操作实现微博微信关注模型
A关注的人: {B, C}
SADD follow:A B C
B关注的人:{A, C, E, F, G, H}
SADD follow:B A C E F G H
C关注的人: {I, G}
SADD follow:C I G
1)A和B共同关注: {C}
SINTER follow:A follow:B
2) 我关注的人也关注他(我关注的人里 关注 我关注的人(C) 的人):
SISMEMBER follow:B C
3) 我可能认识的人(关注我的人关注的人里,我没有关注的人):
SDIFF follow:B follow:A
1) "F"
2) "E"
3) "H"
4) "A"
5) "G"1234567891011121314151617复制代码类型:[java]
集合操作实现电商商品筛选
SADD brand:huawei P40 SADD brand:xiaomi mi-10 SADD brand:iPhone iphone12 SADD os:android P40 mi-10 SADD cpu:brand:intel P40 mi-10 SADD ram:8G P40 mi-10 iphone12 SINTER os:android cpu:brand:intel ram:8G 结果: 1) "P40" 2) "mi-10"12345678910复制代码类型:[java]
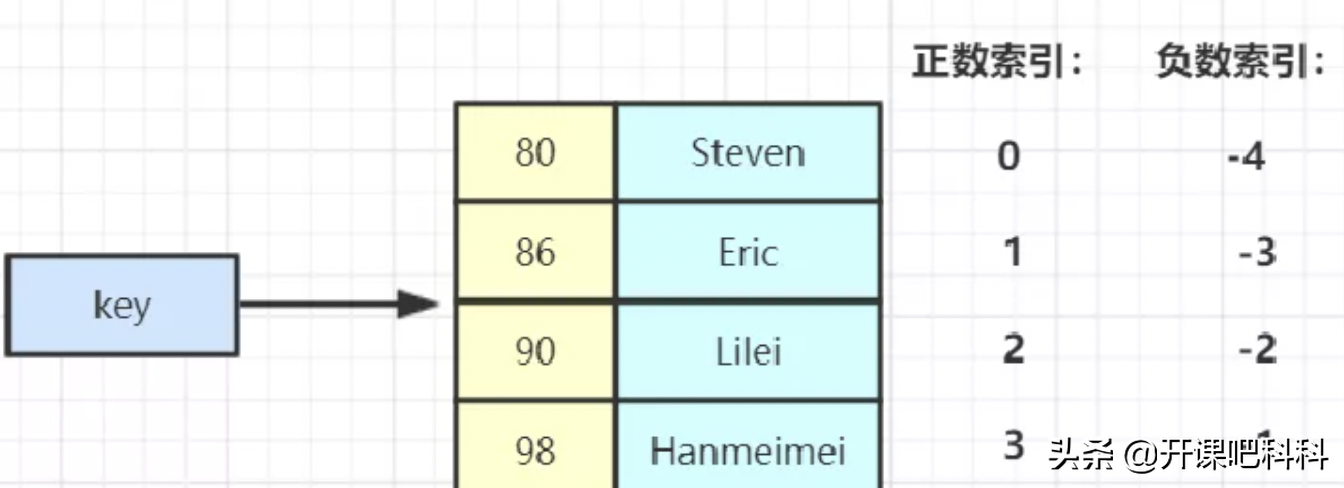
ZSet(SortedSet)
ZSet常用操作
ZADD key score member [[score member]…] //往有序集合key中加入带分值元素 ZREM key member [member …] //从有序集合key中删除元素 ZSCORE key member //返回有序集合key中元素member的分值 ZINCRBY key increment member //为有序集合key中元素member的分值加上increment ZCARD key //返回有序集合key中元素个数 ZRANGE key start stop [WITHSCORES] //正序获取有序集合key从start下标到stop下标的元素 ZREVRANGE key start stop [WITHSCORES] //倒序获取有序集合key从start下标到stop下标的元素1234567复制代码类型:[java]
Zset集合操作
ZUNIONSTORE destkey numkeys key [key ...] //并集计算 ZINTERSTORE destkey numkeys key [key …] //交集计算12复制代码类型:[java]
Zset集合操作实现排行榜
1)点击新闻 ZINCRBY hotNews:20210101 1 2)展示当日排行前十 ZREVRANGE hotNews:20210101 0 9 WITHSCORES 3)七日搜索榜单计算 ZUNIONSTORE hotNews:20210101-20210107 7 hotNews:20210101 hotNews:20210102... hotNews:20210107 4)展示七日排行前十 ZREVRANGE hotNews:20210101-20210107 0 9 WITHSCORES123456789复制代码类型:[java]
Redis 的补充数据类型
BitMap
BitMap 就是通过一个 bit 位来表示某个元素对应的值或者状态, 其中的 key 就是对应元素本身,实际上底层也是通过对字符串的操作来实现。Redis 从 2.2 版本之后新增了setbit, getbit, bitcount 等几个 bitmap 相关命令。虽然是新命令,但是本身都是对字符串的操作,我们先来看看语法:
SETBIT key offset value1复制代码类型:[java]
其中 offset 必须是数字,value 只能是 0 或者 1.offset参数要求大于或等于 0.并且小于 2^32(4.294.967.296),这将位图限制在 512MB
设置最后一个可能的位时(偏移量等于 2^32-1)和存储在键中的字符串值尚不保存字符串值,或持有一个小字符串值,Redis 需要分配所有中间内存,这些中间内存可能会阻塞服务器一段时间。在 2010 年 Macbook Pro 上,设置位号 2^32-1 (512MB 分配) 需要 300 毫秒,设置位数 2^30-1 (128MB 分配) 需要 80 毫秒,设置位数 2^28-1 (32MB 分配) 需要 30 毫秒并设置位号 2^26-1 (8MB 分配) 需要 ±8 毫秒。请注意,完成第一次分配后,对同一key的 SETBIT的后续调用将不具有分配开销。
127.0.0.1:6379> setbit k1 5 1 (integer) 0 127.0.0.1:6379> getbit k1 5 1 (integer) 1 127.0.0.1:6379> getbit k1 4 0 (integer) 0 127.0.0.1:6379> bitcount k1 (integer) 1 127.0.0.1:6379> setbit k1 3 1 (integer) 0 127.0.0.1:6379> bitcount k1 (integer) 2 127.0.0.1:6379> setbit "200522:active" 67 1 (integer) 0 127.0.0.1:6379> setbit "200522:active" 78 1 (integer) 012345678910111213141516复制代码类型:[java]
其中 offset 必须是数字,value 只能是 0 或者 1.通过 bitcount可以很快速的统计,比传统的关系型数据库效率高很多
//对一个或多个保存二进制位的字符串 key 进行位元操作,并将结果保存到 destkey 上 BITOP operation destkey key [key ...] //operation 可以是 AND 、 OR 、 NOT 、 XOR 这四种操作中的任意一种 //对一个或多个 key 求逻辑并,并将结果保存到 destkey BITOP AND destkey key [key ...] 对一个或多个 key 求逻辑或,并将结果保存到 destkey BITOP OR destkey key [key ...] 对一个或多个 key 求逻辑异或,并将结果保存到 destkey BITOP XOR destkey key [key ...] 对给定 key 求逻辑非,并将结果保存到 destkey BITOP NOT destkey key 除了 NOT 操作之外,其他操作都可以接受一个或多个 key 作为输入。123456789101112复制代码类型:[java]
HyperLogLog
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
1.基于bitmap 计数
2.基于概率基数计数
1)线性计数算法
2)对数计数算法(LLC)
3)自适应计数算法
4)超对数计数算法
这个数据结构的命令有三个:PFADD、PFCOUNT、PFMERGE
用途:记录网站IP注册数,每日访问的IP数,页面实时UV、在线用户人数
局限性:只能统计数量,没有办法看具体信息
127.0.0.1:6379> pfadd h1 b (integer) 1 127.0.0.1:6379> pfadd h1 a (integer) 0 127.0.0.1:6379> pfcount h1 (integer) 2 127.0.0.1:6379> pfadd h1 c (integer) 1 127.0.0.1:6379> pfadd h2 a (integer) 1 127.0.0.1:6379> pfadd h3 d (integer) 1 127.0.0.1:6379> pfmerge h3 h1 h2 OK 127.0.0.1:6379> pfcount h3 (integer) 412345678910111213141516复制代码类型:[java]
Geospatial
底层数据结构 Zset
命令:GEOADD、GEODIST、GEOHASH、GEOPOP、GEOPADUIS、GEORADIUSBYMEMBER
可以用来保存地理位置,并作位置距离计算或者根据半径计算位置等。有没有想过用Redis来实现附近的人?或者计算最优地图路径?Geo本身不是一种数据结构,它本质上还是借助于Sorted Set(ZSET)
Redis GEO 操作方法有:
geoadd:添加地理位置的坐标。
geopos:获取地理位置的坐标。
geodist:计算两个位置之间的距离。
georadius:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。
georadiusbymember:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合。
geohash:返回一个或多个位置对象的 geohash 值。
把某个具体的位置信息(经度,纬度,名称)添加到指定的key中,数据将会用一个sorted set存储,以便稍后能使用GEORADIUS和GEORADIUSBYMEMBER命令来根据半径来查询位置信息。
127.0.0.1:6379> GEOADD cities 116.404269 39.91582 "beijing" 121.478799 31.235456 "shanghai" (integer) 2 127.0.0.1:6379> ZRANGE cities 0 -1 1) "shanghai" 2) "beijing" 127.0.0.1:6379> ZRANGE cities 0 -1 WITHSCORES 1) "shanghai" 2) "4054803475356102" 3) "beijing" 4) "4069885555377153" 127.0.0.1:6379> GEODIST cities beijing shanghai km "1068.5677" 127.0.0.1:6379> GEOPOS cities beijing shanghai 1) 1) "116.40426903963088989" 2) "39.91581928642635546" 2) 1) "121.47879928350448608" 2) "31.23545629441388627" 127.0.0.1:6379> GEOADD cities 120.165036 30.278973 hangzhou (integer) 1 127.0.0.1:6379> GEORADIUS cities 120 30 500 km 1) "hangzhou" 2) "shanghai" 127.0.0.1:6379> GEORADIUSBYMEMBER cities shanghai 200 km 1) "hangzhou" 2) "shanghai" 127.0.0.1:6379> ZRANGE cities 0 -1 1) "hangzhou" 2) "shanghai" 3) "beijing" 127.0.0.1:6379>123456789101112131415161718192021222324252627282930复制代码类型:[java]
精确到小数点后6位可以达到约1米精度,所以一般经纬度精确到小数点后6位即可。
Redis 消息模式
队列模式
使用list类型的lpush和rpop实现消息队列
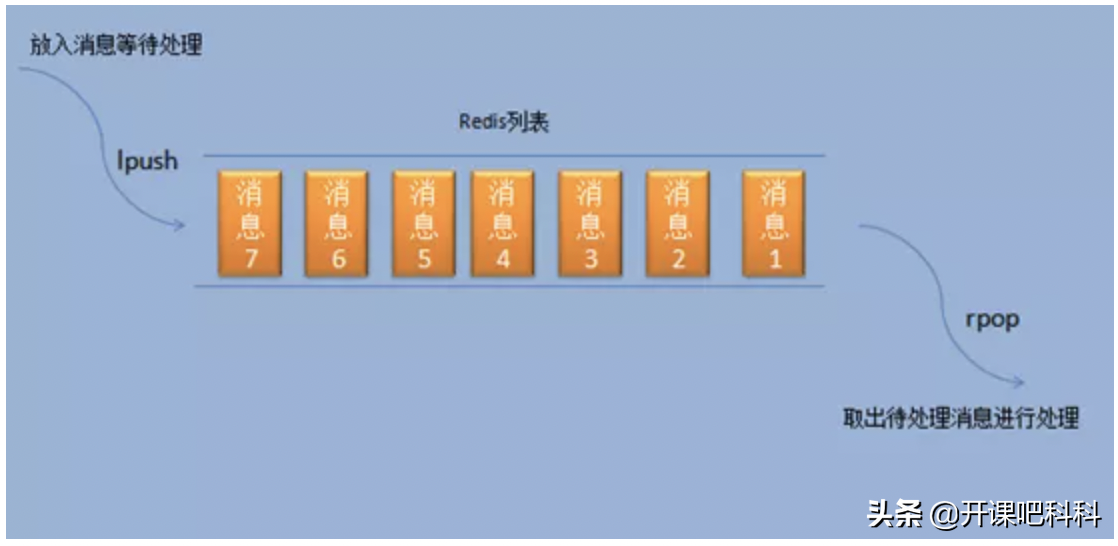
注意事项:
消息接收方如果不知道队列中是否有消息,会一直发送rpop命令,如果这样的话,会每一次都建立一次连接,这样显然不好。
可以使用brpop命令,它如果从队列中取不出来数据,会一直阻塞,在一定范围内没有取出则返回null
缺点:
做消费者确认ACK麻烦,不能保证消费者消费消息后是否成功处理的问题(宕机或处理异常等),通常需要维护一个Pending列表,保证消息处理确认。
不能做广播模式,如pub/sub,消息发布/订阅模型
不能重复消费,一旦消费就会被删除
不支持分组消费
发布订阅模式
SUBSCRIBE,用于订阅信道
PUBLISH,向信道发送消息
UNSUBSCRIBE,取消订阅
此模式允许生产者只生产一次消息,由中间件负责将消息复制到多个消息队列,每个消息队列由对应的消费组消费。
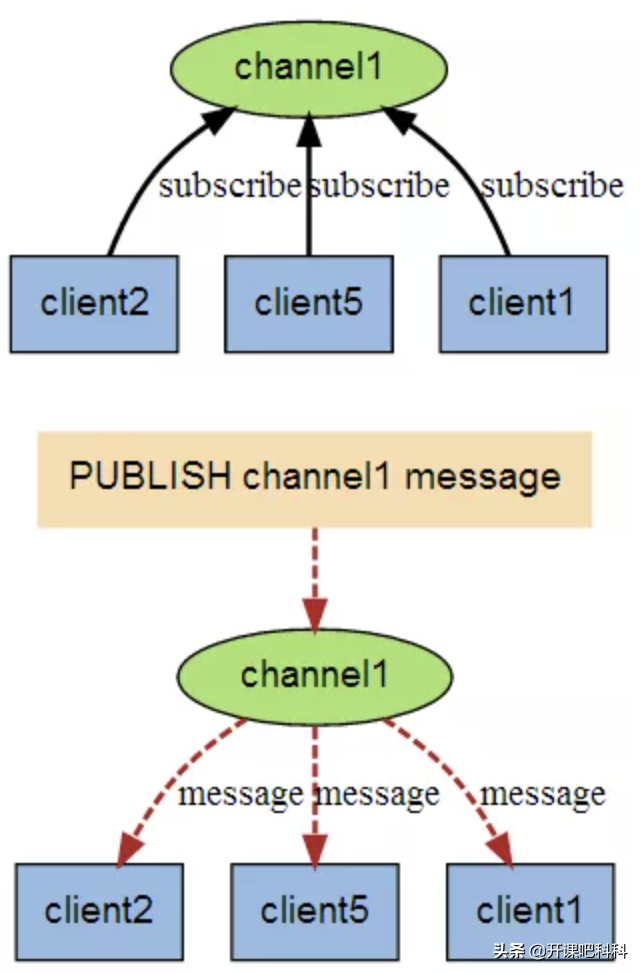
优点
典型的广播模式,一个消息可以发布到多个消费者;多信道订阅,消费者可以同时订阅多个信道,从而接收多类消息;消息即时发送,消息不用等待消费者读取,消费者会自动接收到信道发布的消息
缺点
消息一旦发布,不能接收。换句话就是发布时若客户端不在线,则消息丢失,不能寻回;不能保证每个消费者接收的时间是一致的;若消费者客户端出现消息积压,到一定程度,会被强制断开,导致消息意外丢失。通常发生在消息的生产远大于消费速度时
可见,Pub/Sub 模式不适合做消息存储,消息积压类的业务,而是擅长处理广播,即时通讯,即时反馈的业务。
基于Sorted-Set的实现
Sortes Set(有序列表),类似于java的SortedSet和HashMap的结合体,一方面它是一个set,保证内部value的唯一性,另一方面它可以给每个value赋予一个score,代表这个value的排序权重。内部实现是“跳跃表”。
有序集合的方案是在自己确定消息顺ID时比较常用,使用集合成员的Score来作为消息ID,保证顺序,还可以保证消息ID的单调递增。通常可以使用时间戳+序号的方案。确保了消息ID的单调递增,利用SortedSet的依据Score排序的特征,就可以制作一个有序的消息队列了。
优点
就是可以自定义消息ID,在消息ID有意义时,比较重要。
缺点
缺点也明显,不允许重复消息(因为是集合),同时消息ID确定有错误会导致消息的顺序出错。
Redis Stream
Redis 5.0 全新的数据类型:streams,官方把它定义为:以更抽象的方式建模日志的数据结构。Redis的streams主要是一个append only(AOF)的数据结构,至少在概念上它是一种在内存中表示的抽象数据类型,只不过它们实现了更强大的操作,以克服日志文件本身的限制。
如果你了解MQ,那么可以把streams当做基于内存的MQ。如果你还了解kafka,那么甚至可以把streams当做基于内存的kafka。listpack存储信息,Rax组织listpack 消息链表
listpack是对ziplist的改进,它比ziplist少了一个定位最后一个元素的属性
另外,这个功能有点类似于redis以前的Pub/Sub,但是也有基本的不同:
1、streams支持多个客户端(消费者)等待数据(Linux环境开多个窗口执行XREAD即可模拟),并且每个客户端得到的是完全相同的数据。
2、Pub/Sub是发送忘记的方式,并且不存储任何数据;而streams模式下,所有消息被无限期追加在streams中,除非用于显式执行删除(XDEL)。XDEL 只做一个标记位 其实信息和长度还在
3、streams的Consumer Groups也是Pub/Sub无法实现的控制方式。
streams数据结构本身非常简单,但是streams依然是Redis到目前为止最复杂的类型,其原因是实现的一些额外的功能:一系列的阻塞操作允许消费者等待生产者加入到streams的新数据。另外还有一个称为Consumer Groups的概念,Consumer Group概念最先由kafka提出,Redis有一个类似实现,和kafka的Consumer Groups的目的是一样的:允许一组客户端协调消费相同的信息流!
消息队列相关命令:
XADD - 添加消息到末尾 XTRIM - 对流进行修剪,限制长度 XDEL - 删除消息 XLEN - 获取流包含的元素数量,即消息长度 XRANGE - 获取消息列表,会自动过滤已经删除的消息 XREVRANGE - 反向获取消息列表,ID 从大到小 XREAD - 以阻塞或非阻塞方式获取消息列表1234567复制代码类型:[java]
xxxxxxxxxxbr XADD - 添加消息到末尾brXTRIM - 对流进行修剪,限制长度brXDEL - 删除消息brXLEN - 获取流包含的元素数量,即消息长度brXRANGE - 获取消息列表,会自动过滤已经删除的消息brXREVRANGE - 反向获取消息列表,ID 从大到小brXREAD - 以阻塞或非阻塞方式获取消息列表1234567复制代码类型:[java]
消费者组相关命令:
XGROUP CREATE - 创建消费者组 XREADGROUP GROUP - 读取消费者组中的消息 XACK - 将消息标记为"已处理" XGROUP SETID - 为消费者组设置新的最后递送消息ID XGROUP DELCONSUMER - 删除消费者 XGROUP DESTROY - 删除消费者组 XPENDING - 显示待处理消息的相关信息 XCLAIM - 转移消息的归属权 XINFO - 查看流和消费者组的相关信息; XINFO GROUPS - 打印消费者组的信息; XINFO STREAM - 打印流信息1234567891011复制代码类型:[java]
xxxxxxxxxxbr XGROUP CREATE - 创建消费者组brXREADGROUP GROUP - 读取消费者组中的消息brXACK - 将消息标记为"已处理"brXGROUP SETID - 为消费者组设置新的最后递送消息IDbrXGROUP DELCONSUMER - 删除消费者brXGROUP DESTROY - 删除消费者组brXPENDING - 显示待处理消息的相关信息brXCLAIM - 转移消息的归属权brXINFO - 查看流和消费者组的相关信息;brXINFO GROUPS - 打印消费者组的信息;brXINFO STREAM - 打印流信息1234567891011复制代码类型:[java]
XADD
使用 XADD 向队列添加消息,如果指定的队列不存在,则创建一个队列,XADD 语法格式:
XADD key ID field value [field value ...] key :队列名称,如果不存在就创建 ID :消息 id,我们使用 * 表示由 redis 生成,可以自定义,但是要自己保证递增性。 field value :记录。1234复制代码类型:[java]
xxxxxxxxxxbr XADD key ID field value [field value ...]brkey :队列名称,如果不存在就创建brID :消息 id,我们使用 * 表示由 redis 生成,可以自定义,但是要自己保证递增性。brfield value :记录。1234复制代码类型:[java]
XTRIM
使用 XTRIM 对流进行修剪,限制长度, 语法格式:
XTRIM key MAXLEN [~] count key :队列名称 MAXLEN :长度 count :数量1234复制代码类型:[java]
xxxxxxxxxxbr XTRIM key MAXLEN [~] countbrkey :队列名称brMAXLEN :长度brcount :数量1234复制代码类型:[java]
XDEL
使用 XDEL 删除消息,语法格式:
XDEL key ID [ID ...] key:队列名称 ID :消息 ID123复制代码类型:[java]
xxxxxxxxxxbr XDEL key ID [ID ...]brkey:队列名称brID :消息 ID123复制代码类型:[java]
XLEN
使用 XLEN 获取流包含的元素数量,即消息长度,语法格式:
XLEN key key:队列名称12复制代码类型:[java]
xxxxxxxxxxbr XLEN keybrkey:队列名称12复制代码类型:[java]
XRANGE
使用 XRANGE 获取消息列表,会自动过滤已经删除的消息 ,语法格式:
XRANGE key start end [COUNT count] key :队列名 start :开始值, - 表示最小值 end :结束值, + 表示最大值 count :数量12345复制代码类型:[java]
xxxxxxxxxxbr XRANGE key start end [COUNT count]brkey :队列名brstart :开始值, - 表示最小值brend :结束值, + 表示最大值brcount :数量12345复制代码类型:[java]
XREVRANGE
使用 XREVRANGE 获取消息列表,会自动过滤已经删除的消息 ,语法格式:
XREVRANGE key end start [COUNT count] key :队列名 end :结束值, + 表示最大值 start :开始值, - 表示最小值 count :数量12345复制代码类型:[java]
xxxxxxxxxxbr XREVRANGE key end start [COUNT count]brkey :队列名brend :结束值, + 表示最大值brstart :开始值, - 表示最小值brcount :数量12345复制代码类型:[java]
XREAD
使用 XREAD 以阻塞或非阻塞方式获取消息列表 ,语法格式:
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...] count :数量 milliseconds :可选,阻塞毫秒数,没有设置就是非阻塞模式 key :队列名 id :消息 ID #非阻塞,查询id>0的所有的消息>XREAD COUNT 2 STREAMS stream1 0-0 #stream中存储的最大ID作为最后一个ID> xread block 0 streams stream1 $1234567复制代码类型:[java]
xxxxxxxxxxbr XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]brcount :数量brmilliseconds :可选,阻塞毫秒数,没有设置就是非阻塞模式brkey :队列名brid :消息 IDbr#非阻塞,查询id>0的所有的消息>XREAD COUNT 2 STREAMS stream1 0-0br#stream中存储的最大ID作为最后一个ID> xread block 0 streams stream1 $1234567复制代码类型:[java]
以上是XREAD的非阻塞形式。注意COUNT选项并不是必需的,实际上这个命令唯一强制的选项是STREAMS,指定了一组key以及调用者已经看到的每个Stream相应的最大ID,以便该命令仅向客户端提供ID大于我们指定ID的消息。
第二条命令指定了新的BLOCK选项,超时时间为0毫秒(意味着永不超时)。此外,并没有给流 mystream传入一个常规的ID,而是传入了一个特殊的ID$。这个特殊的ID意思是XREAD应该使用流 mystream已经存储的最大ID作为最后一个ID。
XGROUP CREATE
使用 XGROUP CREATE 创建消费者组,语法格式:
XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername] key :队列名称,如果不存在就创建 groupname :组名。 $ :表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略。 从头开始消费: XGROUP CREATE mystream consumer-group-name 0-0 从尾部开始消费: XGROUP CREATE mystream consumer-group-name $12345678复制代码类型:[java]
xxxxxxxxxxbr XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername]brkey :队列名称,如果不存在就创建brgroupname :组名。br$ :表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略。br从头开始消费:brXGROUP CREATE mystream consumer-group-name 0-0br从尾部开始消费:brXGROUP CREATE mystream consumer-group-name $12345678复制代码类型:[java]
XREADGROUP GROUP
使用 XREADGROUP GROUP 读取消费组中的消息,语法格式:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...] group :消费组名 consumer :消费者名。 count :读取数量。 milliseconds :阻塞毫秒数。 key :队列名。 ID :消息 ID。 XREADGROUP GROUP consumer-group-name consumer-name COUNT 1 STREAMS mystream >12345678复制代码类型:[java]
xxxxxxxxxxbr XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]brgroup :消费组名brconsumer :消费者名。brcount :读取数量。brmilliseconds :阻塞毫秒数。brkey :队列名。brID :消息 ID。brXREADGROUP GROUP consumer-group-name consumer-name COUNT 1 STREAMS mystream >12345678复制代码类型:[java]
在以上命令行中还有另外一个非常重要的细节在强制选项STREAMS之后,键mystream请求的ID是特殊的ID >。这个特殊的ID只在消费者组的上下文中有效,其意思是:消息到目前为止从未传递给其他消费者。
实例:
//发布消息
127.0.0.1:6379> xadd mystream * message apple
"1589994652300-0"
127.0.0.1:6379> xadd mystream * message orange
"1589994679942-0"
//读取消息
127.0.0.1:6379> xrange mystream - +
1) 1) "1589994652300-0"
2) 1) "message"
2) "apple"
2) 1) "1589994679942-0"
2) 1) "message"
2) "orange"
//阻塞读取
xread block 0 streams mystream $
//发布新消息
127.0.0.1:6379> xadd mystream * message strawberry
//创建消费组
127.0.0.1:6379> xgroup create mystream mygroup1 0
OK
127.0.0.1:6379> xgroup create mystream mygroup2 0
OK123456789101112131415161718192021222324复制代码类型:[java]
xxxxxxxxxxbr //发布消息br127.0.0.1:6379> xadd mystream * message applebr"1589994652300-0"br127.0.0.1:6379> xadd mystream * message orangebr"1589994679942-0"brbr//读取消息br127.0.0.1:6379> xrange mystream - +br1) 1) "1589994652300-0"br 2) 1) "message"br 2) "apple"br2) 1) "1589994679942-0"br 2) 1) "message"br 2) "orange"brbr//阻塞读取brxread block 0 streams mystream $br//发布新消息br127.0.0.1:6379> xadd mystream * message strawberrybr//创建消费组br127.0.0.1:6379> xgroup create mystream mygroup1 0brOKbr127.0.0.1:6379> xgroup create mystream mygroup2 0brOK123456789101112131415161718192021222324复制代码类型:[java]
通过消费组读取消息
127.0.0.1:6379> xreadgroup group mygroup1 zange count 2 streams mystream >
1) 1) "mystream"
2) 1) 1) "1589994652300-0"
2) 1) "message"
2) "apple"
2) 1) "1589994679942-0"
2) 1) "message"
2) "orange"
127.0.0.1:6379> xreadgroup group mugroup1 tuge count 2 streams mystream >
1) 1) "mystream"
2) 1) 1) "1589995171242-0"
2) 1) "message"
2) "strawberry"
127.0.0.1:6379> xreadgroup group mugroup2 tuge count 1 streams mystream >
1) 1) "mystream"
2) 1) 1) "1589995171242-0"
2) 1) "message"
2) "apple"12345678910111213141516171819复制代码类型:[java]
xxxxxxxxxxbr 127.0.0.1:6379> xreadgroup group mygroup1 zange count 2 streams mystream >br1) 1) "mystream"br 2) 1) 1) "1589994652300-0"br 2) 1) "message"br 2) "apple"br 2) 1) "1589994679942-0"br 2) 1) "message"br 2) "orange"br127.0.0.1:6379> xreadgroup group mugroup1 tuge count 2 streams mystream >br1) 1) "mystream"br 2) 1) 1) "1589995171242-0"br 2) 1) "message"br 2) "strawberry"brbr127.0.0.1:6379> xreadgroup group mugroup2 tuge count 1 streams mystream >br1) 1) "mystream"br 2) 1) 1) "1589995171242-0"br 2) 1) "message"br 2) "apple"12345678910111213141516171819复制代码类型:[java]
数据类型有几种?
我们先创建一下几种类型,然后通过type命令来查看一下
127.0.0.1:6379> SET string:key value OK 127.0.0.1:6379> LPUSH list:key 10001 (integer) 1 127.0.0.1:6379> HMSET hash:key 1:name A 1:age 18 OK 127.0.0.1:6379> SADD set:key 1001 1002 (integer) 2 127.0.0.1:6379> ZADD zset:key 100 wang (integer) 1 127.0.0.1:6379> setbit bitmap:key 5 1 (integer) 0 127.0.0.1:6379> pfadd hyperloglog:key b (integer) 1 127.0.0.1:6379> GEOADD geo:key 116.404269 39.91582 "beijing" 121.478799 31.235456 "shanghai" (integer) 2 127.0.0.1:6379> XADD stream:key 10001 field value "10001-0" 127.0.0.1:6379> PUBLISH runoobChat "Redis PUBLISH test" (integer) 0 127.0.0.1:6379> keys * 1) "geo:key" 2) "bitmap:key" 3) "stream:key" 4) "set:key" 5) "string:key" 6) "hyperloglog:key" 7) "zset:key" 8) "hash:key" 9) "list:key" 127.0.0.1:6379> TYPE geo:key zset 127.0.0.1:6379> TYPE bitmap:key string 127.0.0.1:6379> TYPE stream:key stream 127.0.0.1:6379> TYPE set:key set 127.0.0.1:6379> TYPE string:key string 127.0.0.1:6379> TYPE hyperloglog:key string 127.0.0.1:6379> TYPE zset:key zset 127.0.0.1:6379> TYPE hash:key hash 127.0.0.1:6379> TYPE list:key list123456789101112131415161718192021222324252627282930313233343536373839404142434445464748复制代码类型:[java]
xxxxxxxxxxbr 127.0.0.1:6379> SET string:key value brOKbr127.0.0.1:6379> LPUSH list:key 10001br(integer) 1br127.0.0.1:6379> HMSET hash:key 1:name A 1:age 18brOKbr127.0.0.1:6379> SADD set:key 1001 1002br(integer) 2br127.0.0.1:6379> ZADD zset:key 100 wangbr(integer) 1br127.0.0.1:6379> setbit bitmap:key 5 1br(integer) 0br127.0.0.1:6379> pfadd hyperloglog:key bbr(integer) 1br127.0.0.1:6379> GEOADD geo:key 116.404269 39.91582 "beijing" 121.478799 31.235456 "shanghai"br(integer) 2br127.0.0.1:6379> XADD stream:key 10001 field valuebr"10001-0"br127.0.0.1:6379> PUBLISH runoobChat "Redis PUBLISH test"br(integer) 0br127.0.0.1:6379> keys *br1) "geo:key"br2) "bitmap:key"br3) "stream:key"br4) "set:key"br5) "string:key"br6) "hyperloglog:key"br7) "zset:key"br8) "hash:key"br9) "list:key"br127.0.0.1:6379> TYPE geo:keybrzsetbr127.0.0.1:6379> TYPE bitmap:keybrstringbr127.0.0.1:6379> TYPE stream:keybrstreambr127.0.0.1:6379> TYPE set:keybrsetbr127.0.0.1:6379> TYPE string:keybrstringbr127.0.0.1:6379> TYPE hyperloglog:keybrstringbr127.0.0.1:6379> TYPE zset:keybrzsetbr127.0.0.1:6379> TYPE hash:keybrhashbr127.0.0.1:6379> TYPE list:keybrlist123456789101112131415161718192021222324252627282930313233343536373839404142434445464748复制代码类型:[java]
由此可见,redis实际是有6种数据类型的,bitmap和hyperloglog的数据类型其实是String,geo的类型其实是zset,redis 5之后又加了一种stream,所以是6种,bitmap和hyperloglog还有geo的数据类型是跟他们的实现原理有关的,接下来的几次课,咱们来一起研究redis是如何实现这几种数据类型的