最近在学习编写接口自动化,在代码的调试及以后的自动化集成过程中,避免不了会产生许多测试数据。日积月累,这些使用过的无用数据会长期存放在数据库当中,一来会占用空间,二来页面也会一直展示。由于项目本身并没有对历史数据进行删除的操作需求,只得连接数据库,从数据库表中将这些无用数据进行删除。由此,本文将简单的对数据库进行介绍与操作。
背景介绍
在互联网行业兴起的今日,数据不断信息化,各行各业都开始使用各种程序进行数据的管理,向无纸化存储进行过渡,对程序进行操作,必定会产生大量数据。这些数据是需要做持久化处理及后期维护的。所以合理的利用数据库可以高效、有组织地存储数据,可以使人们能够从大量信息中,更加快速地提取自己所需要的。
数据库相比于传统纸质化管理,优点主要表现在以下几个方面:
(1)传统纸质在大量数据面前不能快速检索,容量也不足以与数据库进行对比。增加容量就相当于增加成本。利用数据库,设计的合理主外键,可以优化查询效率和降低数据的冗余。
(2)在许多情况下,将数据放入数据库也是出于安全原因。如果把账号密码都放在纸质文件中,那么机密性会降低。水火无情,也不排除这些因素对纸质的损坏。将其存放在数据库中并进行加密,并及时对数据库进行备份,可以极大程度地保证数据的安全性。
(3)数据库技术可以和智能分析联动,产出新的有用信息。如今的大数据分析,就是将大量的真实数据进行提取和判断,从而对其分析产生新的结论。如根据用户的个人喜好,提取用户浏览和购买的记录信息,结合推荐算法,面向广大用户推送符合自己口味的商品或短视频。
1. 数据库的分类
在如今的互联网中,最常见的数据库模型主要是两种,即关系型数据库和非关系型数据库:
1.1 关系型数据库
简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由多个二维表使用主外键连接所组成的一个数据组织。
关系模型中常用的概念:
(1)关系:可以理解为一张二维表,每个关系都具有一个关系名,就是通常说的表名。
(2)属性:可以理解为二维表中的一列,在数据库中经常被称为字段。
(3)域:属性的取值范围,也就是数据库中某一列的取值限制。
(4)关键字:数据库中常称为主键,由一个或多个列组成。
关系型数据库的优点:
- 容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解。
- 使用方便:通用的SQL语言使得操作关系型数据库非常方便。
- 易于维护:丰富的完整性,大大减低了数据冗余和数据不一致的概率。
当然,关系型数据库也有它的瓶颈:
高并发读写时,可能每秒有高达上万次的读写请求,对于传统关系型数据库来说,硬盘I/O是一个很大的瓶颈。
当产生巨大的数据量时,对于关系型数据库来说,查询效率会不断降低,即使不断对SQL查询进行优化,也会有一个上限,始终无法突破。
1.2 非关系型数据库分类
非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
面向高性能并发读写的key-value数据库:
key-value数据库的主要特点是具有极高的并发读写性能,例如:Redis,其数据按照键值对的形式进行组织、索引和存储,将key值与value值进行映射。可将其作为缓存,存入内存中。这样就不需要为每个单独的请求重新渲染页面,达到快速响应的目的。
面向海量数据访问的文档数据库:
这类数据库的特点是,可以在海量的数据中快速的查询数据,典型代表为MongoDB,它是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持类似于json的bson格式,因此可以存储比较复杂的数据类型。
2. 数据库的常用操作
2.1 关系型数据库
本文以MySQL为例,简单介绍常用的操作语句。现在大多数服务器都是部署在Linux上的,所以需要使用指令完成:
(1)启用:进入终端输入“service mysqld start”,即可启用mysql
(2)查看状态:进入终端输入“service mysqld status”,即可查看mysql的启用状态
(3)停止:进入终端输入“service mysqld stop”,即可停止启用mysql
(4)登录mysql:mysql -u 用户名 -p 用户密码 。例如(用户名:zhangsan,密码:123):mysql -u zhangsan -p 123
(5)创建数据库:create database 数据库名
(6)删除数据库:drop database 数据库名
(7)使用数据库:use database 数据库名
(8)创建表格:
- create table 表名(
- -> id int not null auto_increment, //新增一个叫id的整型字段,不能为空,自增长列
- -> title varchar(100) not null, //新增一个叫title的字符串字段,不能为空
- -> primary key ( id )//将id设为主键
- -> )ENGINE=InnoDB default charset=utf8;//使用InnoDB数据库引擎,将数据库表用utf8(中文)进行编码存储
(9)删除数据库表:drop table 表名
(10)新增数据库表数据:insert into 表名 (字段1, 字段2, ..., 字段n) values (值1, 值2, ..., 值n);
(11)删除数据:delete from 表名 where title="测试"
(12)查询数据库表: * 查询所有字段: select * from 表名;
- 查询部分字段: select 字段1,字段2 from 表名;
- 根据条件查询(where后面跟查询条件):select * from 表名 where title="测试";
- 多表查询:select * from 表名A,表名B where 表A.title=表B.title;
- 模糊查询: select * from 表名 where title like '%测试%';
- 根据某个字段正倒序查询:select * from 表名 order by title desc/asc ; // 按升序排列默认使用,可不写:asc ,按降序排列:desc
2.2 非关系型数据库
本文以MongoDB为例,简单介绍常用的操作语句。现在大多数服务器都是部署在Linux上的,所以需要使用指令完成:
(1)启用:需要进入终端,cd进入mongodb目录下的bin文件夹下,使用./mongo
(2)查看状态:进入终端输入netstat -lanp | grep "mongodb端口号",即可查看MongoDB的启用状态
(3)停止:./mongod -shutdown;
(4)登录:mongo --host IP地址 -u 用户名 --authentication Database 数据库名 -p 密码//例如:用户名zhangsan,密码123:mongo --host 127.0.0.1 -u zhangsan --authentication Database admin -p 123
(5)创建数据库:use 数据库名,当use的时候,如果数据库不存,则系统就会自动创建,如存在,会进行切换
(6)删除数据库:db.dropDatabase(),必须要先use待删除的数据库,然后再调用此语句
(7)创建集合:db.createCollection("集合名")
(8)删除集合:db.集合名.drop()
(9)新增文档: var_data1 = {name:'张三',age:10,sex:"男"}; db.集合名.insert(var_data1)
(10)删除文档:db.集合名.remove({"name":"张三"}) (11)查询文档:
- 查询所有文档:db.集合名.find().pretty();
- 根据条件查询:db.集合名.find({"age":10})
- 正倒序查询:db.集合名.find().sort({"price" : 1}) // 1:按升序排列 -1:按降序排列
- 模糊查询: db.集合名.find({name: /张三/});
3. 数据库远程操作软件
上一点介绍了使用linux的命令行连接数据库,当然也可以使用远程连接工具进行数据库的可视化访问,这里以Navicat Premium 15为例,简单介绍MySQL和mongoDB的远程连接及常用的操作。
3.1 MySQL数据库
(1)选择“文件”-“新建链接”-“MySQL”
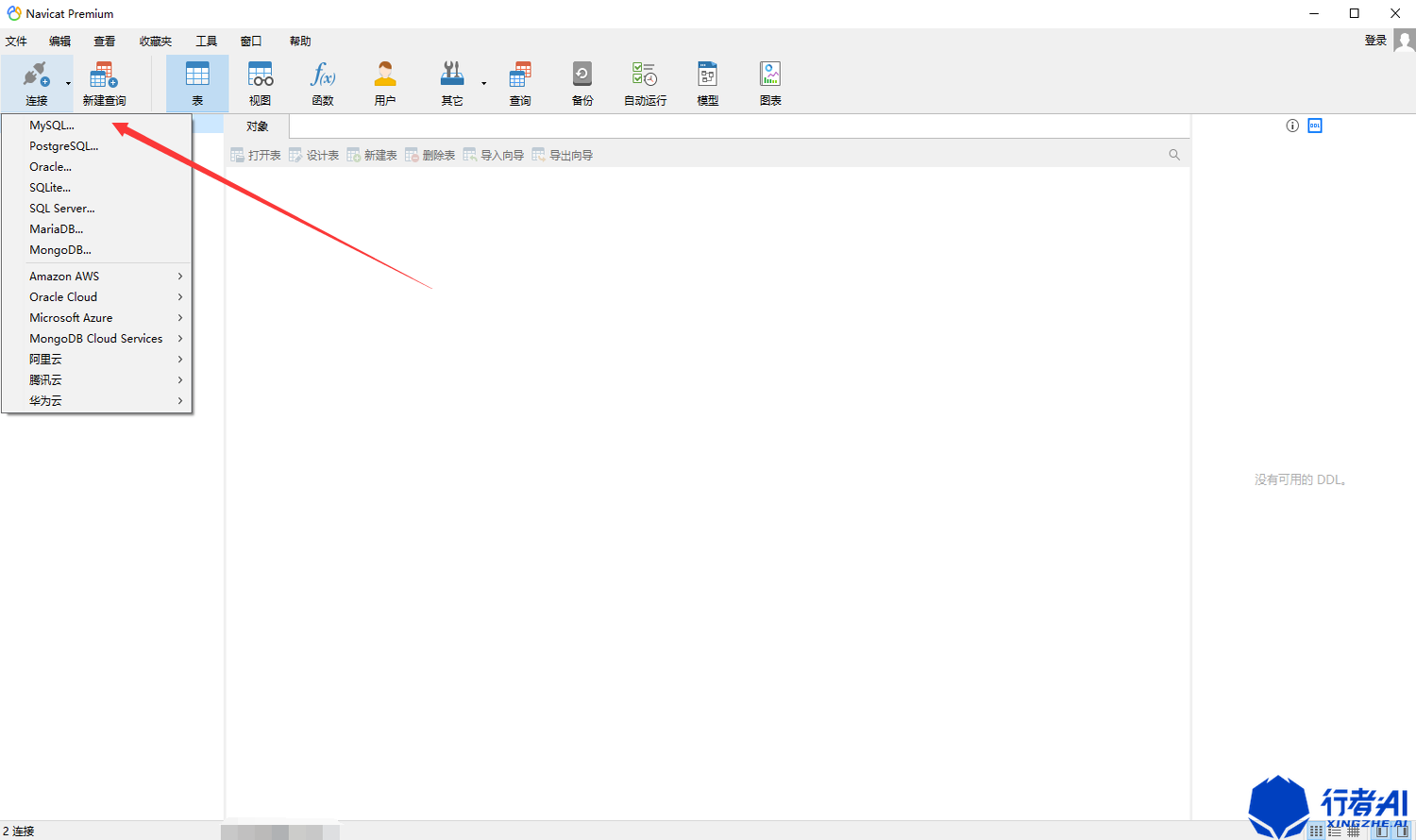
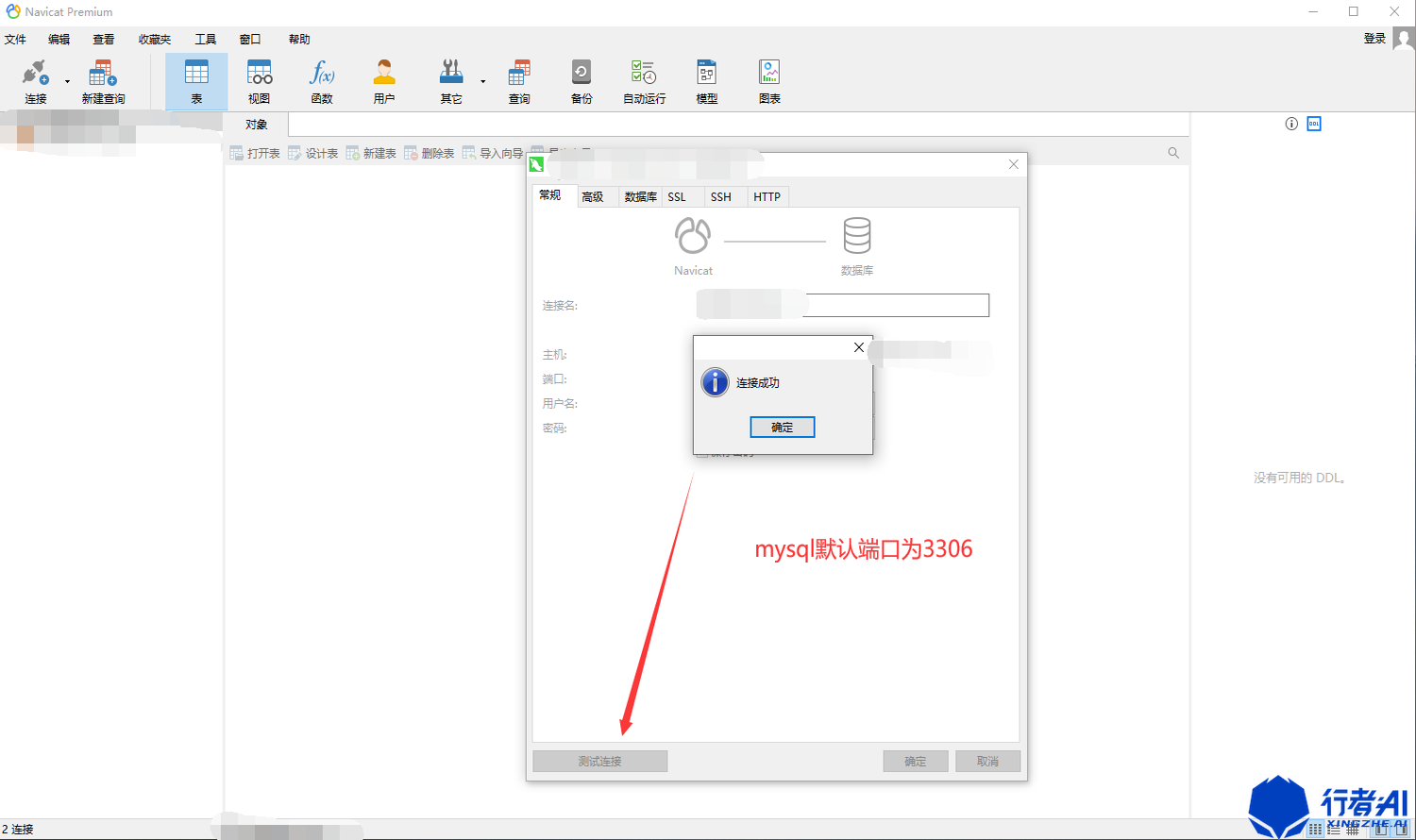
(2)输入需要连接的数据库信息,点击测试连接,如果提示成功即可使用
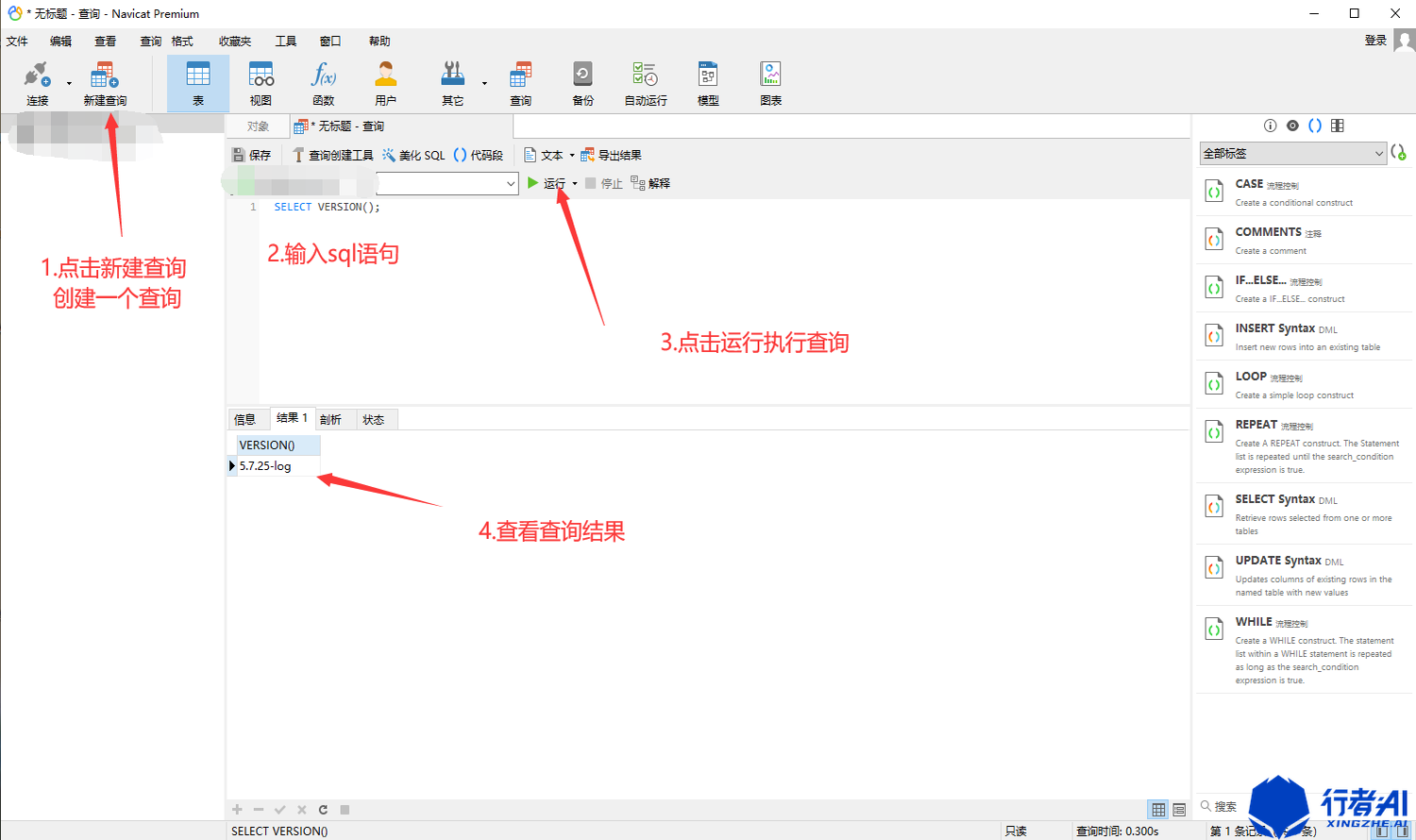
(3)点击新建查询,输入SQL语句,即可执行
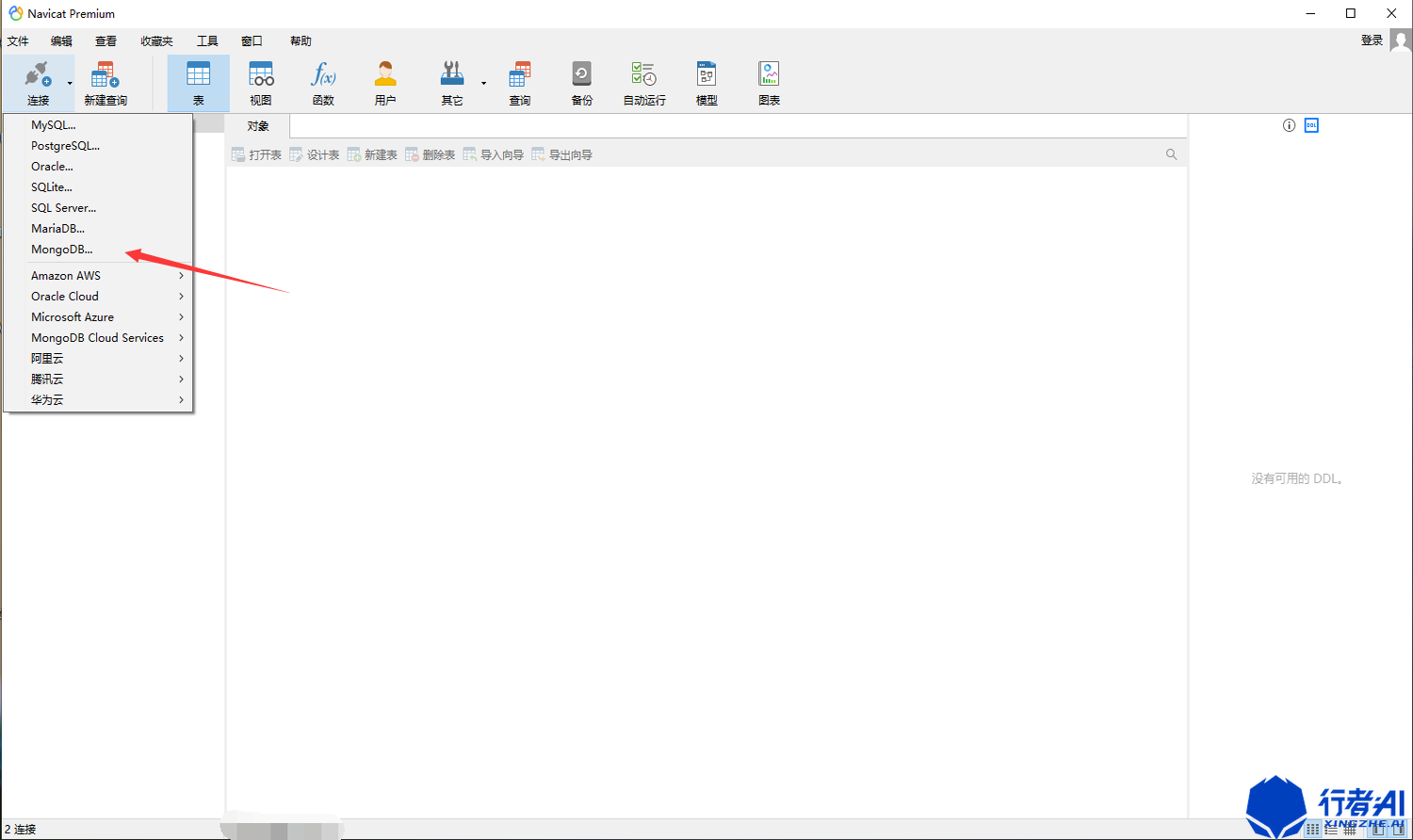
3.2 MongoDB数据库
(1)选择“连接”-“MongoDB”
(2)如果有认证,则需要选择“password”
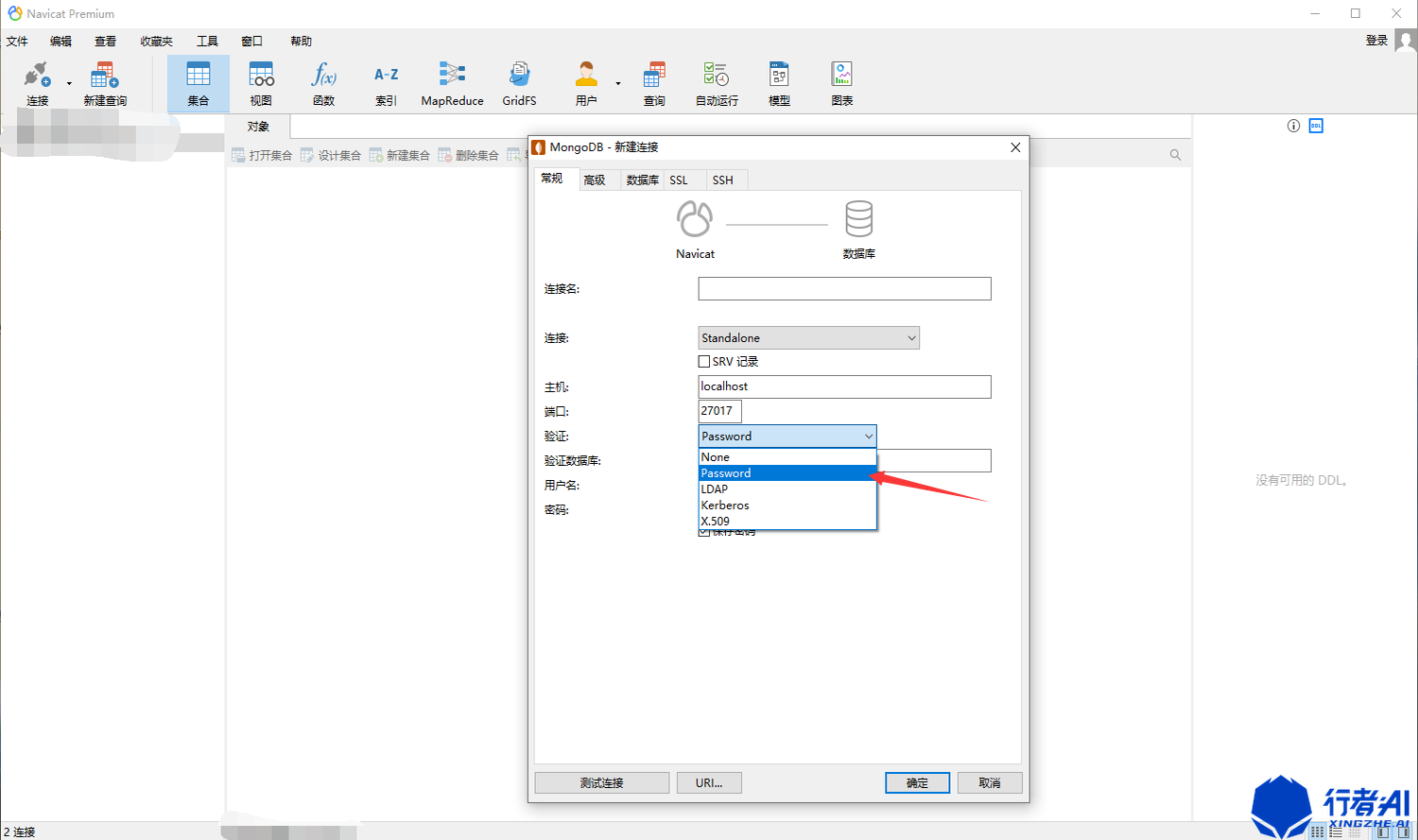
(3)输入需要连接的数据库信息,点击测试连接,如果提示成功即可使用

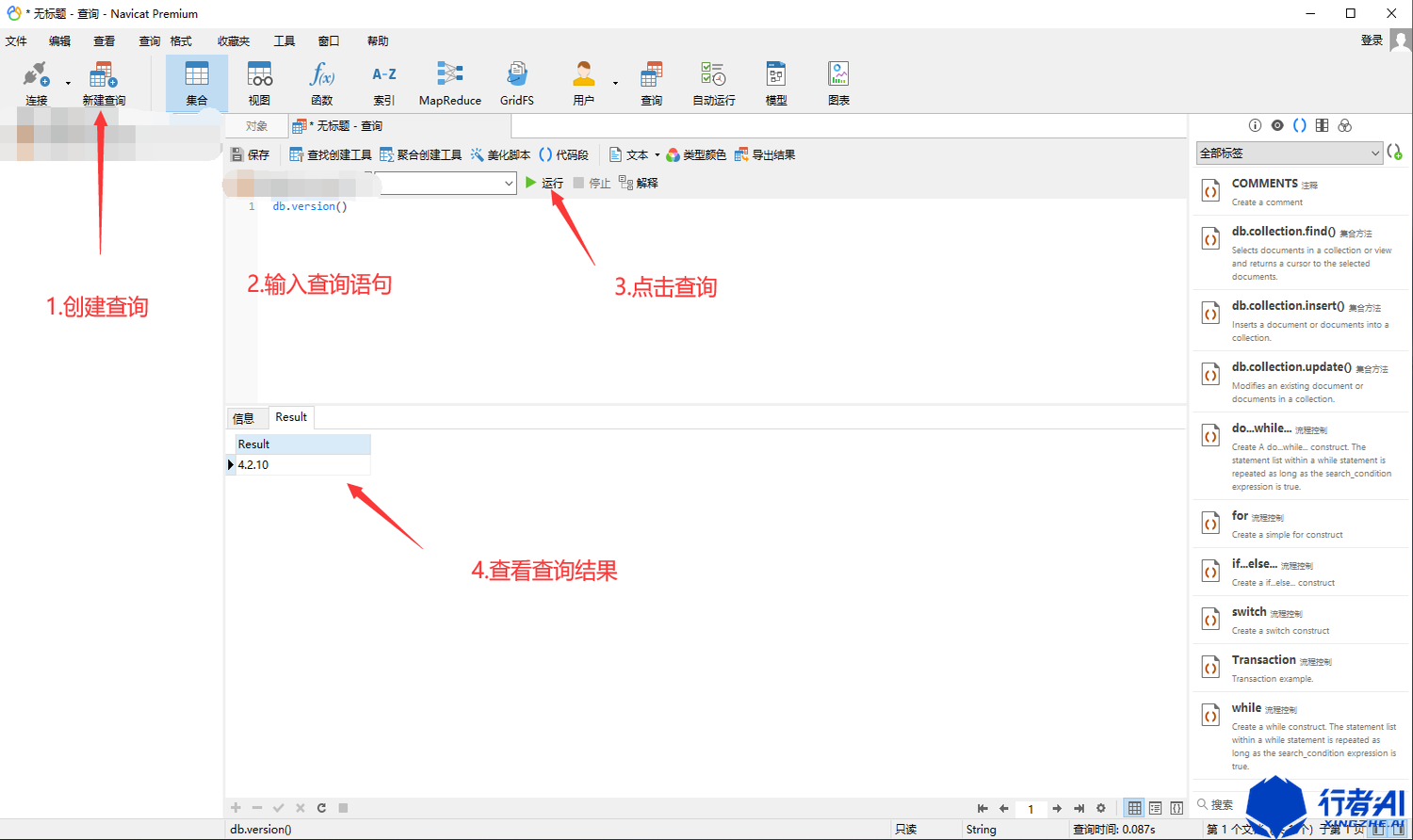
(4)点击新建查询,输入SQL语句,即可执行
4. 总结
在学习自动化的同时,也对数据库有了进一步的了解。通过查看数据库表的设计,可以更深入的理解项目的架构和业务。这样可以帮助我们在今后的测试工作中,发现更多的潜在缺陷。本文也只是简单叙述了一些常用的数据库语句,当面对较为复杂的数据库操作时,这些显然是不够用的,这也给我找到了另一个可以学习的方向,使自己不断完善,更加全面。