昨天,由于工作需要,要从PDF文档中复制出文字,把它上线到网站。这没有多大技术含量、搬运工的活,之前一直被我所不齿,可是逐渐的发现处处留心皆学问。。。
结合自己的操作习惯,PDF文档的阅读是选用Abobe Acrobat Pro DC软件,版本自然是最新的2018.011.20040。区别于Adobe Acrobat Reader DC只能进行阅电脑读,Pro DC版本是可以进行PDF编辑的。
Abobe Acrobat Pro DC软件
最初觉得,既然已经选择了收(zhuang)费(bi)的顶配版本,文字的识别能力应该没啥问题,奈何,原本如此清晰而且可编辑的文字,复制出来的结果却如此不能忍。。。
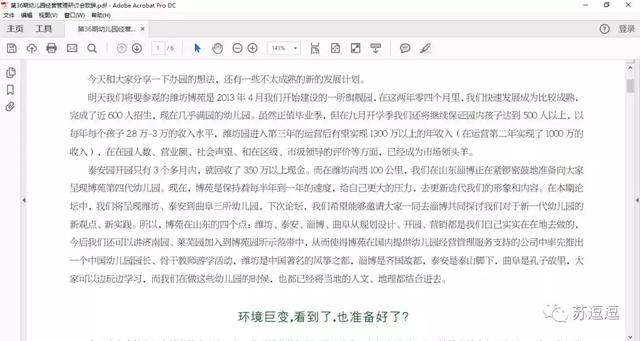
PDF源文件
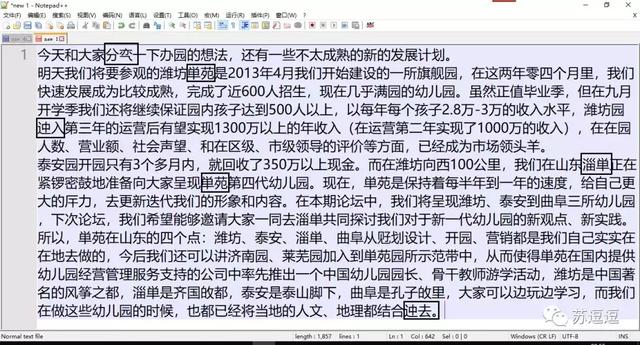
复制结果
如果仅仅只有这一个文档,动手纠正下,也是忍忍就过去了。。。可是面对一二十篇的PDF文档要进行复制和编辑,如何才能提高工作效率,这便成了一个问题。
要做复制的文件
于是,我开始探索解决这个问题的办法。
一般来说,想要获得PDF文档中的解决办法有以下两种。
1、对于清晰度较高的文档,直接用PDF阅读器打开,直接全选进行复制。
2、清晰度一般的文档或者被保护的文档难以通过复制到正确的文字,可以将PDF文档转换为图片的格式,之后采取OCR技术。如使用ABBYY或者Onenote等OCR识别软件进行处理。

Onenote 2016
对于昨天遇到的问题,清晰度足够高,选择第一种方法是速度最快的方法,然而,复制出来的文字不但出现了大量的错字,而且复制出来的段落还有大量的空格。。。
复制出的结果
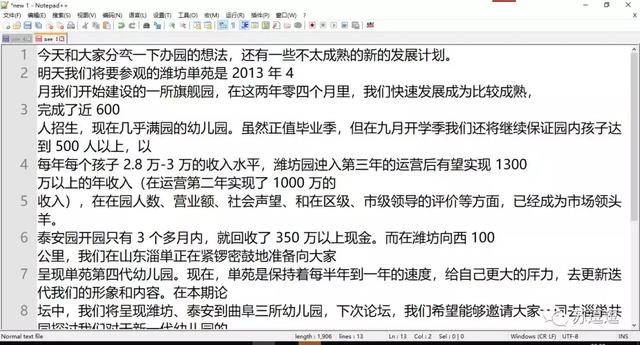
遇到这个问题以后,对此结果的第一判断就是,文字的识别引擎估计是不行。。。于是,我先后选择了PDF阅读器的备胎Google Chrome、Microsoft Edge、Opera、Cent Browser、Word,即使换用了这么几款软件之后,结果都还是挺让人失望的。。。
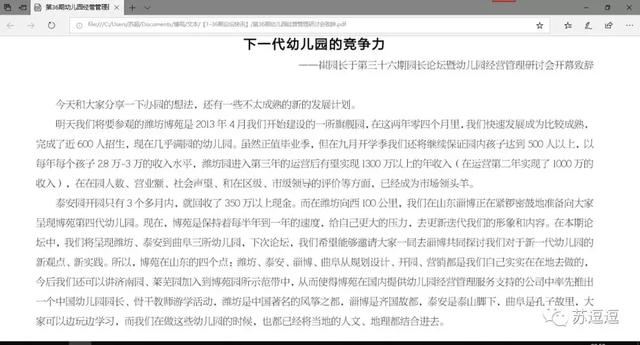
Microsoft Edge打开的文件
 电脑
电脑Microsoft Edge的识别结果
Opera的阅读效果
Opera的识别结果
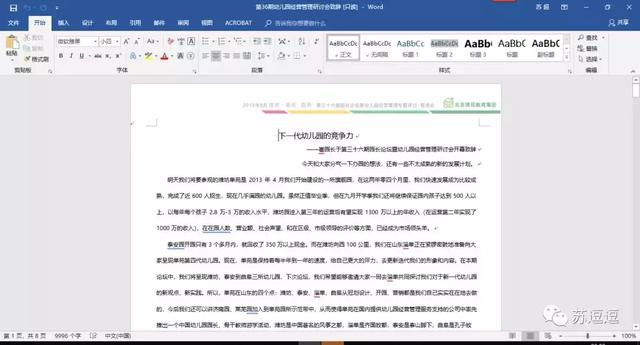
word打开的PDF文件
经历了这么多步骤,之后,我只好放弃使用第一种方案。只能选择备用方案Abobe Acrobat Pro DC打开PDF文档,选择到处JPEG和PNG图片的格式,然后选用Oneonte 2016去识别。
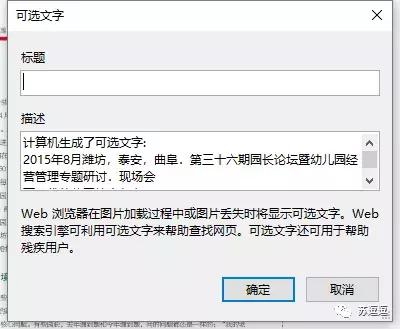
Onenote 2016 OCR识别
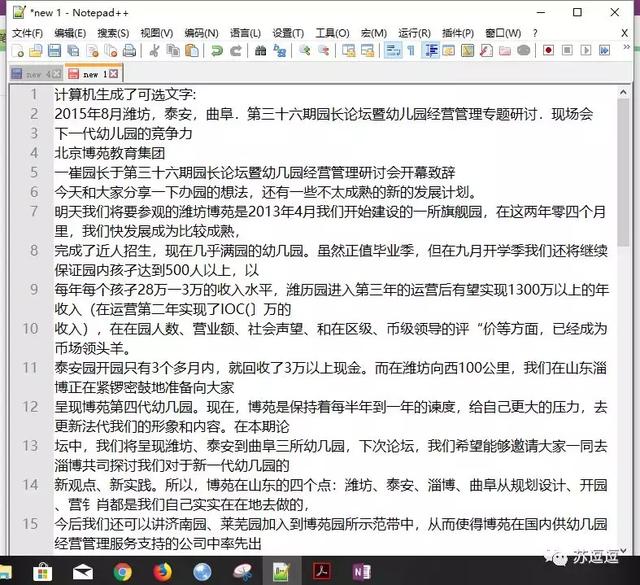
Onenote 2016 OCR识别结果
错别字的错误率虽说降低了不少,但是,这样一步一步折腾下来,还是挺复杂的。。。
于是,问题再次回到原点。。。
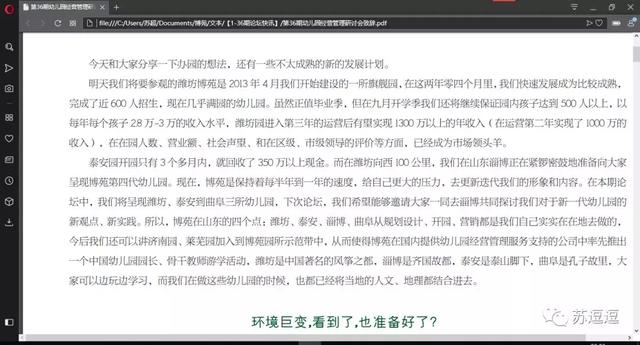
突发奇想,既然Abobe Acrobat Pro DC可以进行PDF编辑,为何不去尝试一下呢,转机出现了。。。进入编辑模式下,复制出来的文字就没有任何错别字了。
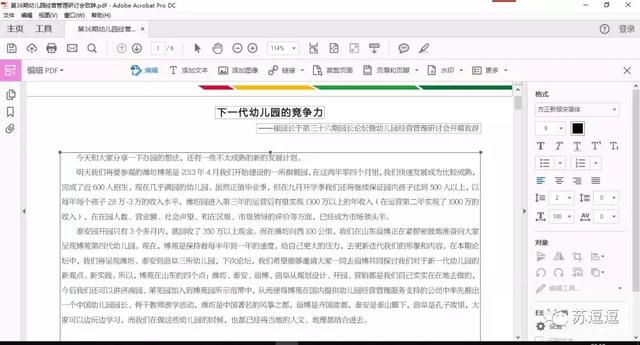
PDF文档
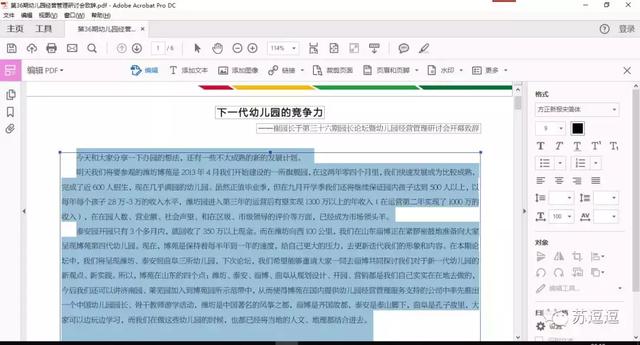
PDF文档复制
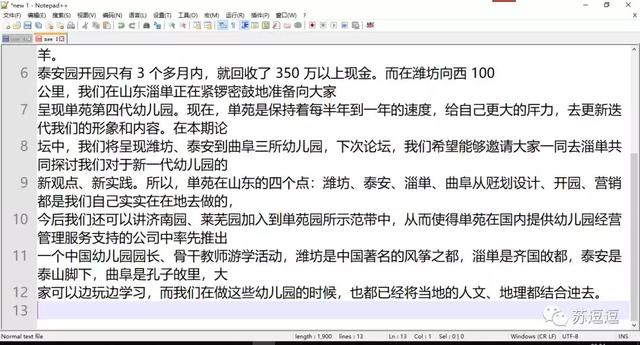
输出结果
到了这一步,我发现,PDF中的文档的字体是方正新报宋简体,猜测也许是电脑中并无这个字体,所以导致字体在打开模式下的识别正确率低。
于是,我就来对自己的猜测进行了验证。
当我把字体下载下来,安装到电脑上之后,再次在查看模式下进行复制操作,结果证明,我的猜测是错误的。不过这也正好验证了避免其他软件产生的不兼容和字体替换问题的特性。
由此可见,PDF文件在阅读模式下,字体已经被原本制作PDF文件的软件特殊处理,以此在阅读的模式下不会出现乱码。
在解决了复制文件出错的问题以后,再次出现了一个问题。
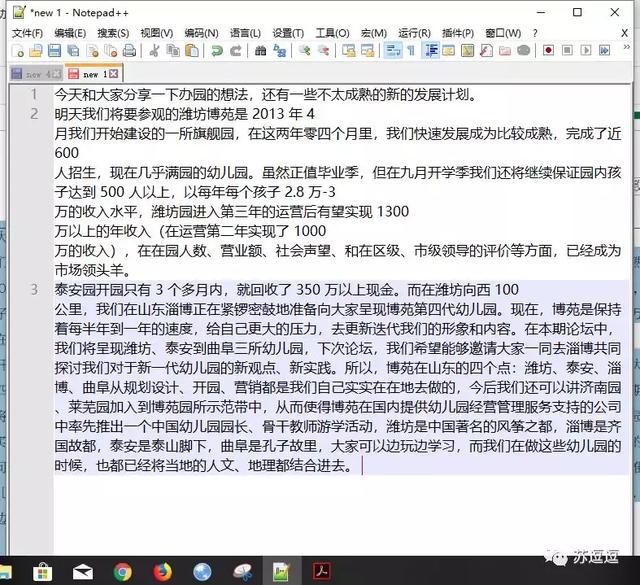
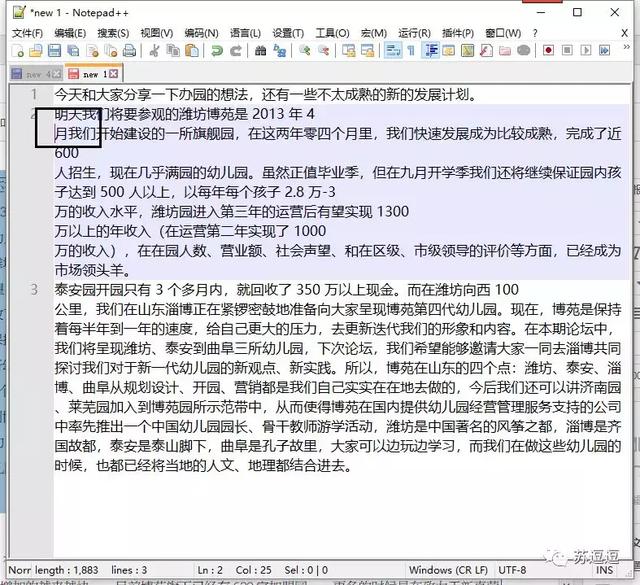
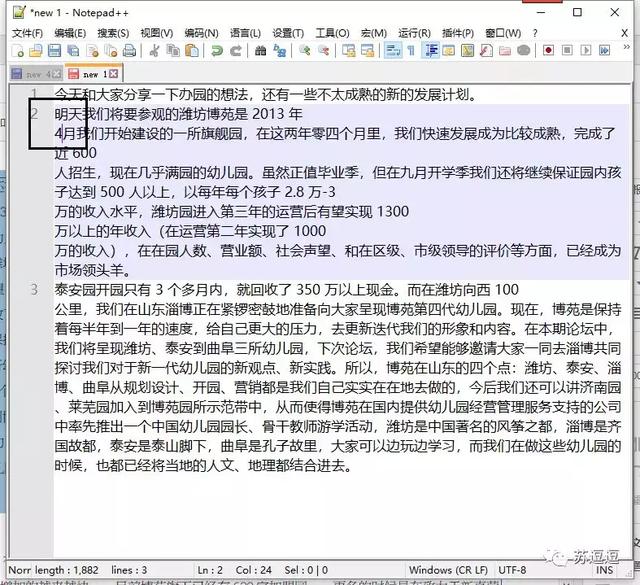
复制过来的段落文字中的数字总是会和之后的文字分行。如果进行手动拆行的话,会发现一个奇怪的现象。看似只需一次的退格操作后即可完成的任务,实际上却并没有成功。
手动修改格式步骤1
手动修改格式步骤2
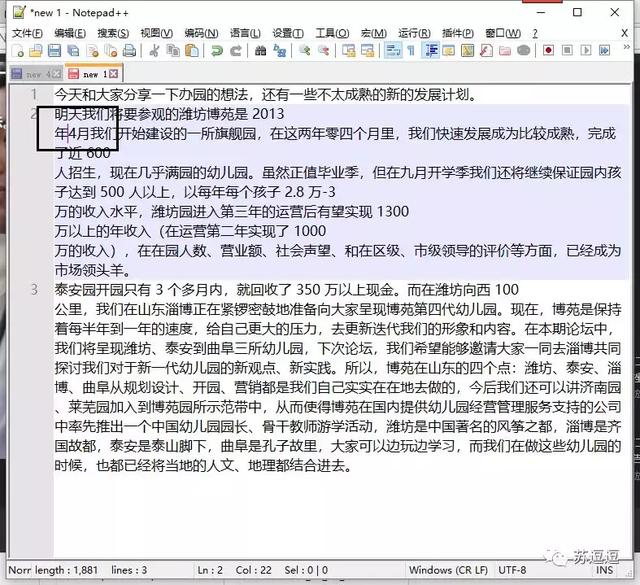
手动修改格式步骤3(N步才能做好)
我对此段落进行了行操作的移除空行和空白以及编辑菜单中的移除空白字符,想了好久,最终还是用上了查找替换大法。。。查找空格,替换空白即可。
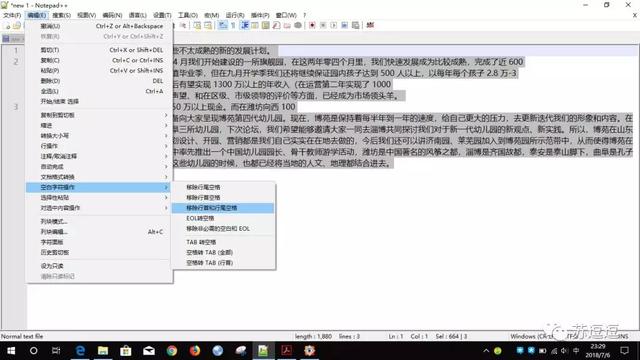
清除空格操作(无法解决问题)
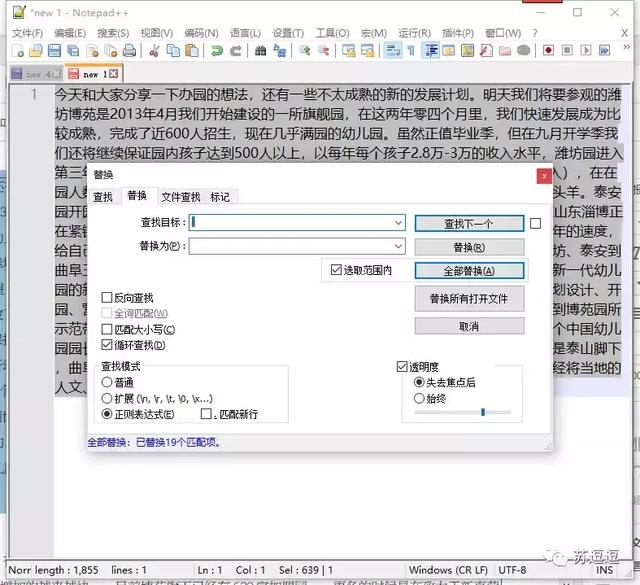
一步搞定